计算机组成原理-实验5
文章发布地址:
- https://type.dayiyi.top/index.php/archives/253/
- https://www.cnblogs.com/rabbit-dayi/p/17832279.html(更快,但是排版差一点)
- https://blog.dayi.ink/?p=109
- https://cmd.dayi.ink/H_paf5lXTb6E2Oi4xxPIYw?both (文章源站,国外CDN,比较慢)
ALU设计
只实现 + - and or 就可以啦。不用编码这么多。
这个 A、B、ALUOP是一个叫隧道的东西。

编码如下:
0 0 0 +
0 0 1 -
0 1 0 and
0 1 1 or
1 0 0 x
1 0 1 ÷
1 1 0 比较
1 1 1 移位比较:
>时输出00000000=时输出00000001<时输出00000011
移位:
A - 二进制
B - 向左移动几位 (仅前三位有效)

模拟运算
加法
1+2 = 3

减法
2-1 = 1
AND运算

OR 运算

乘法运算
$1*2 = 2$

除法运算
$2/4 = 2$

比较运算
大于输出0

等于输出1

小于输出2
移位运算

设计汉字显示系统
0. 任务分解
0.1 什么是国标 GB2312-1980
1981-05-01实施 根据2017年第7号公告和强制性标准整合精简结论,自2017年3月23日起,该标准转化为推荐性标准,不再强制执行。
- GB2312 就是那个跟UTF-8相互转换,直接暴力读取得到著名的“锟斤拷烫烫烫”。
https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=5664A728BD9D523DE3B99BC37AC7A2CC

由两个8位二进制组成一个位,16位二进制表示一个字符

总共94*94 的格子
- 区位码=区号+位号[1-94,1-94]
- 国标码=区位码+32[(1-94)+32,(1-94)+32]
0.2 分解
- 设计一个汉字显示系统,可以显示一首诗。
分解为以下子任务:
- 需要一个显示器来显示汉字。
- 需要一个驱动显示器的芯片。
- 需要进行地址和字符位置的对应。
- 需要一个字库来存储汉字的点阵信息。
- 需要一个计算器来将汉字的编码转换为区位码。
- 需要将诗句存储到ROM中。
- 需要一个触发器来不断计数,从ROM中读取下一个地址的诗句并显示。
1.先把计算机组成原理4的“阵列”画出来
因为是 8个16K 32 位寄存器,所以要这样画
10位是1KB(1024byte)
10位 * 2^4 = 16KB

2. 把ROM加载上数据
根据国标 GB2312-1980,设计一个包含所有汉字的字库。
每个汉字用一个16位的二进制数表示,总共有94*94个汉字。
将字库存储到ROM中。
- 找到这8个文件

- 然后找到你滴电路图!
点击加载数据

- 要对应好。
hz0 -> D1
hz1 -> D2
hz2 -> D3
hz3 -> D4
hz4 -> D5
hz5 -> D6
hz6 -> D7
hz7 -> D8这样就把字库加载进来了。
其实就是把编码对应到点阵的译码器。
字库,没那么高级,就是把一个字符的在阵列上的哪个点给打印出来了。
这个电路的作用是,输入一个按区位码排列的字库中的序号,因为这个库只有
3. 封装
- 点这个

- 你要调整好这几个引脚顺序,第一个是D1 最下面一个是D8

对应的时候,点任意一个针脚,然后右下角会出现在原理图中的对应的位置:

- 然后你可以自己调一调,写点字什么的,就可以了。
4. 显示字的电路
- 先新建电路:

- 然后把他拖出来,画个电路图

5. 显示字
国标码
- 查表:
比如说你要显示这个"豆"

对应的是22区25
- 计算
- A等于区
- B等于该区第几个
$(A - 1) * 94 + (B-1)$
$(22-1)*94+(25-1)=1998$
这个1998就是第1998个字,对于编码来说,地址要顺序编码比较省空间,但是对于咱们来说,xx区xx个字比较符合我们的认知
- 转换为二进制:
>>> bin(int("1998",10))
'0b11111001110'
>>>11111001110
具体的:
00011111001110
前导零补上,使总共14位
也可以倒着填进去
这就出来了。
你也可以这样
用这个信息与编码.exe来直接换


总之,咱们需要把A区第B个字符,换成区位码。
6. 计算器电路
也就是把区位码转换为第几个字。
把上述的计算过程自动化,也就是自动区位码。
考虑:输入一个数字,输出相应的区位码
而对于这些芯片的存储,咱们为了方便,直接导入,但会导致把两两个16e二进制读成一个32位进制。
6.1 问题
为了方便,我们直接在文本里存储2913,表示"江"这个字。
但是,存储到ROM中,再读出来会导致读出来的是16进制。
- 2913 江
- 读出来就是0x2913 而不是 0x29 和 0x13
- 并且 这个2913是十进制下的意义。
- 29表示29区,13表示第13个。

- 但是我们读入的是0x2913(16进制下)这样就会出现问题。
6.2 如何分开
- 考虑如何分开?
- 其实很简单,先分成 0x29(16位二进制) 0x13(16位二进制),这一步用分离器即可。
为什么可以直接分?
0x29
00101001
观察一下,0x2对应0010,0x9 对应1001
是不是正好前8位和后八位!对于0x29
- 再次分离 0x2(前8位) 和 0x9(后8位)
- 然后 0x2*10 + 0x9 = 0x1d = 29(十进制)
对于0x13
- 同理,0x1 0x3
- 0x1*10 +0x3 = 0xd = 13 (十进制)
6.3 具体实现
具体实现就简单啦。
把这个十六进制分开,分离一次,再加起来。

0x41
你要把这个0x41
然后再把它带入到AB运算一下即可。
最后的电路
输入29,13。输出2644
也就是输入区位码,输出在GB2312的第几个字。
6.4 更换数据
输入A 0x41
输入B 0x29
输出十进制下的3788
这里我分了两位出来,然后又合起来,计算
$4 * 10 + 1 = 41$(十进制)
$2 * 10 + 9 = 29$ (十进制)
这样先分开再合起来。

最后实现计算器电路:

跟指导书上是一个了。
7. 测试
输入0x41 和 0x29
输出"山"

8. 编码文字
我在干什么)
- 直接编码出就来了。
- 4129 是区位码 41区第29个字,要算出第几个字,但是我们的计算电路已经将这个过程实现完成。
- 所以我们需要把古诗文转换为:
区位码,区位码和区位码之间空格隔开即可。
<!--
因为区位码和汉字非常好转换,网上的工具也非常的多。
但是想要这个41和29就比较难了。
实际上,也不是那么需要这个41和29,只需要两个数按规定计算出来得出3788即可。

所以想法子把他转回来。
还记得计算公式吗?
$(A - 1) * 94 + (B-1) =RES$
AB的范围:
区位码把GB2312字符集分为94个区,每区含有94个位,共8836个码位,其中部分码位未安排字符。
- $A \le 94$
- $B \le 94$
很显然,这两个条件没法直接解方程。

这样就可以啦。
没法逆推就暴力,反正只需要结果是3788,实际上得到3788,A B 应该也是唯一的。你可以自己想一想,如果有解,则AB是唯一解。
ls = list(map(int,input().split()))
ans = []
def calc(res):
# 遍历可能的A和B的值
for A in range(1, 95):
for B in range(1, 95):
if (A - 1) * 94 + (B - 1) == res:
print(f"A: {A}, B: {B}")
return (A,B)
for i in ls:
ans.append(calc(i))
print("ans:")
print(ans)
for i,v in enumerate(ans):
if v==None:
print("[error]:"+str(ls[i]))
continue
print("%02d%02d"%(v[0],v[1]),end=" ")
这样就可以把你好呀转换出来。
4002 2904 5342 0431 4002 2904 5342
-->
9. 江雪
注意,英文字符可能会转换失败!
《江雪》【唐】柳宗元,千山鸟飞绝,万径人踪灭。孤舟蓑笠翁,独钓寒江雪。
区位码:
0122 2913 4909 0123 0130 4438 0131 3388
5558 5210 0312 3907 4129 3681 2341 3088
0312 4582 3022 4043 5557 3580 0103 2534
5459 4382 8350 4644 0312 2232 2186 2614
2913 4909 0103 如果字数比较多的话,要回车的话也挺麻烦的
写错了的脚本的部分,舍不得扔掉

ls = list(map(int,input().split()))
ans = []
for i in ls:
if not 0000<=i<=9999:
print("error_not4:"+str(ls[i]))
continue
ans.append((i//100,i%100))
print("----------------------------")
f = open("out_res","w")
f.write("v2.0 raw\n")
print("v2.0 raw")
cnt = 0
for i,v in enumerate(ans):
cnt+=1
if v==None:
print("[error]:"+str(ls[i]))
continue
print("%02d%02d"%(v[0],v[1]),end=" ")
f.write("%02d%02d "%(v[0],v[1]))
if cnt==8:
cnt = 0
print()
f.write("\n")
print()
然后把这个文件导入即可


另外,这种负的就是转换错了的,你输入的可能是英文

10.导入数据

11.效果


GIF:
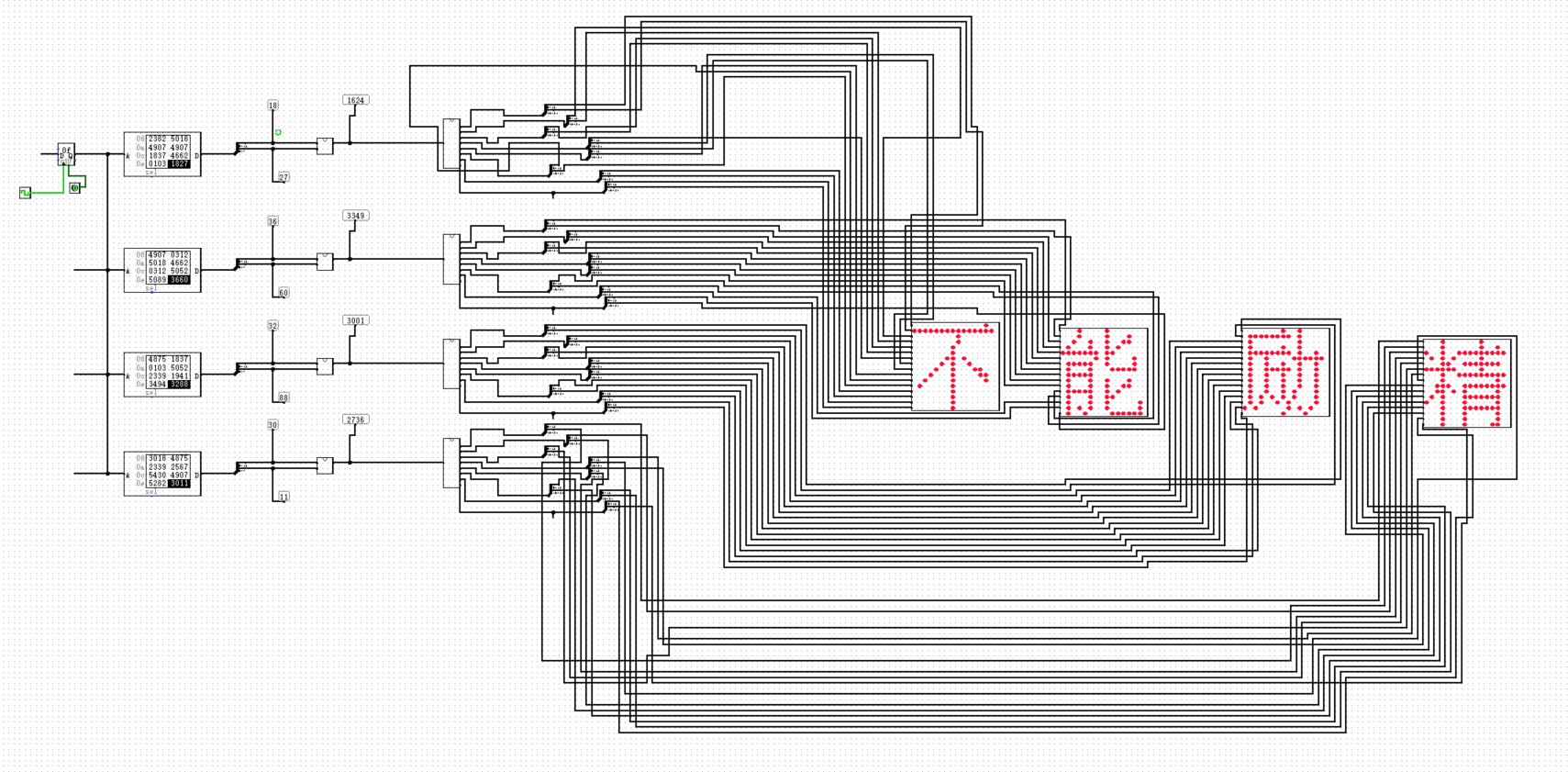
12. 4字
有些时候,有人不是很喜欢玩原神(我自己也不玩),那样如何让我喜欢上玩原神呢?
一下来4个屏幕!

滚字

在计数器信号,每个显示器加1,然后这样,就可以滚字了。


GIF:

滚字-核舟记
明有奇巧人曰王叔远,能以径寸之木,为宫室、器皿、人物,以至鸟兽、木石,罔不因势象形,各具情态。尝贻余核舟一,盖大苏泛赤壁云。舟首尾长约八分有奇,高可二黍许。中轩敞者为舱,箬篷覆之。旁开小窗,左右各四,共八扇。启窗而观,雕栏相望焉。闭之,则右刻“山高月小,水落石出”,左刻“清风徐来,水波不兴”,石青糁之。船头坐三人,中峨冠而多髯者为东坡,佛印居右,鲁直居左。苏、黄共阅一手卷。东坡右手执卷端,左手抚鲁直背。鲁直左手执卷末,右手指卷,如有所语。东坡现右足,鲁直现左足,各微侧,其两膝相比者,各隐卷底衣褶中。佛印绝类弥勒,袒胸露乳,矫首昂视,神情与苏、黄不属。卧右膝,诎右臂支船,而竖其左膝,左臂挂念珠倚之——珠可历历数也。舟尾横卧一楫。楫左右舟子各一人。居右者椎髻仰面,左手倚一衡木,右手攀右趾,若啸呼状。居左者右手执蒲葵扇,左手抚炉,炉上有壶,其人视端容寂,若听茶声然。其船背稍夷,则题名其上,文曰“天启壬戌秋日,虞山王毅叔远甫刻”,细若蚊足,钩画了了,其色墨。又用篆章一,文曰“初平山人”,其色丹。通计一舟,为人五;为窗八;为箬篷,为楫,为炉,为壶,为手卷,为念珠各一;对联、题名并篆文,为字共三十有四。而计其长曾不盈寸。盖简桃核修狭者为之。嘻,技亦灵怪矣哉!转换出来:
v2.0 raw
3587 5148 3870 3941 4043 5227 4585 4269
5222 0312 3660 5052 3022 2071 5414 3630
0312 4610 2512 4250 0102 3887 3583 0102
4043 4679 0312 5052 5433 3681 4262 0102
3630 4215 0312 5672 1827 5082 4238 4783
4846 0312 2487 3063 3973 4412 0103 1902
7461 5164 2643 5459 5027 0312 2439 2083
4353 2326 1964 1758 5238 0103 5459 4255
4618 1904 5228 1643 2354 5148 3870 0312
2463 3141 2294 4282 4877 0103 5448 4889
1908 5363 4610 1853 0312 8372 3781 2418
5414 0103 3752 3110 4801 2016 0312 5583
5150 2487 4336 0312 2518 1643 4140 0103
3884 2016 2288 2559 0312 2181 3224 4764
4591 4941 0103 1753 5414 0312 5282 5150
3144 0116 4129 2463 5234 4801 0312 4314
3468 4215 1986 0117 0312 5583 3144 0116
3969 2371 4876 3220 0312 4314 1808 1827
4843 0117 0312 4215 3964 8454 5414 0103
2012 4523 5588 4093 4043 0312 5448 2275
2558 2288 2264 8755 5363 4610 2211 3834
0312 2380 5101 3051 5150 0312 3419 5417
3051 5583 0103 4353 0102 2738 2518 5236
5027 4254 3077 0103 2211 3834 5150 4254
5420 3077 2243 0312 5583 4254 2407 3419
5417 1719 0103 3419 5417 5583 4254 5420
3077 3609 0312 5150 4254 5424 3077 0312
4071 5148 4389 5179 0103 2211 3834 4754
5150 5567 0312 3419 5417 4754 5583 5567
0312 2487 4602 1864 0312 3868 3329 4705
4764 1740 5363 0312 2487 5094 3077 2155
5034 8162 5448 0103 2380 5101 3088 3264
3554 3253 0312 4427 4856 3422 4073 0312
2935 4255 1626 4251 0312 4181 3973 5175
4353 0102 2738 1827 4284 0103 4652 5150
4705 0312 5816 5150 1759 5407 2012 0312
2288 4290 3868 5583 4705 0312 5583 1759
2550 3678 5473 5048 5414 0110 0110 5473
3141 3290 3290 4293 5018 0103 5459 4618
2665 4652 5027 7314 0103 7314 5583 5150
5459 5551 2487 5027 4043 0103 3051 5150
5363 5521 8757 4986 3570 0312 5583 4254
5048 5027 2666 3630 0312 5150 4254 3742
5150 5426 0312 4084 4805 2684 5520 0103
3051 5583 5363 5150 4254 5420 3849 3191
4140 0312 5583 4254 2407 3415 0312 3415
4147 5148 2688 0312 3868 4043 4251 2243
4061 2837 0312 4084 4493 1872 4189 4027
0103 3868 2012 1719 4152 5036 0312 5282
4466 3591 3868 4147 0312 4636 5227 0116
4476 3884 4041 4871 3979 4053 0312 5161
4129 4585 5067 4269 5222 2406 3144 0117
0312 4724 4084 4635 5567 0312 2519 2713
3343 3343 0312 3868 4111 3611 0103 5154
5135 5513 5334 5027 0312 4636 5227 0116
1985 3829 4129 4043 0117 0312 3868 4111
2104 0103 4508 2838 5027 5459 0312 4610
4043 4669 0327 4610 2016 1643 0327 4610
8372 3781 0312 4610 7314 0312 4610 3415
0312 4610 2688 0312 4610 4254 3077 0312
4610 3678 5473 2487 5027 0327 2252 3310
0102 4466 3591 1802 5513 4636 0312 4610
5554 2518 4093 4214 
字数有点多,加下位宽:


GIF:

瞬间显示--戒子篇
直接生成4个数据文件:
那样如何编码下字符?
没关系,在刚才的脚本上改一改

夫君子之行,静以修身,俭以养德。非淡泊无以明志,非宁静无以致远。夫学须静也,才须学也。非学无以广才,非志无以成学。淫漫则不能励精,险躁则不能治性。年与时驰,意与日去,遂成枯落,多不接世。悲守穷庐,将复何及!def quwei_to_char(area, pos):
byte1 = area + 0xA0
byte2 = pos + 0xA0
gb2312_bytes = bytes([byte1, byte2])
return gb2312_bytes.decode('gb2312')
def split_input_to_files(input_codes):
ans = []
for code in input_codes:
if not 0000 <= code <= 9999:
print("error_not4:" + str(code))
continue
ans.append((code // 100, code % 100))
# 按照位置分配汉字到不同的文件
files_content = {1: "", 2: "", 3: "", 4: ""}
for i, (area, pos) in enumerate(ans):
file_number = (i % 4) + 1
files_content[file_number] += "%02d%02d "%(area,pos)
# 保存到文件
for file_number in range(1, 5):
with open(f"file_{file_number}.txt", "w", encoding='utf-8') as file:
content = files_content[file_number]
words = content.split()
output = ""
for i, word in enumerate(words):
output += word + " "
if (i + 1) % 8 == 0: # 每8个单词添加一个换行符
output += "\n"
file.write("v2.0 raw\n")
file.write(output)
# 测试
input_codes = [4126, 3927, 4421, 4527, 4633] # 一二三四五 的区位码
input_codes = list(map(int,input().split()))
print("待转换内容:")
for i in input_codes:
print(quwei_to_char(i // 100,i % 100),end="")
split_input_to_files(input_codes)

然后自动生成数据文件
数据文件1:
v2.0 raw
2382 4848 4862 5052 2339 5052 2339 5052
2382 5018 4907 4907 1837 4662 0103 1827
0312 1827 0103 1959 4053 1941 2264 0103
3414 2646 数据文件2:
v2.0 raw
3093 0312 4177 4988 2113 3587 3694 5434
4907 0312 5018 4662 0312 5052 5089 3660
4753 3660 3674 0312 4005 3161 1827 1715
0312 2816 数据文件3:
v2.0 raw
5551 3018 0312 2134 1820 5430 3018 5222
4875 1837 0103 5052 2339 1941 3494 3288
5274 5446 5175 5066 0312 3468 2951 4256
2911 0301 数据文件4:
v2.0 raw
5414 5052 2883 0103 4662 0312 4662 0103
3018 4875 2339 2567 5430 4907 5282 3011
5282 4852 4217 5175 4376 0312 4232 3978
2420 加载数据:



GIF:

横过来;
有点..
GIF:
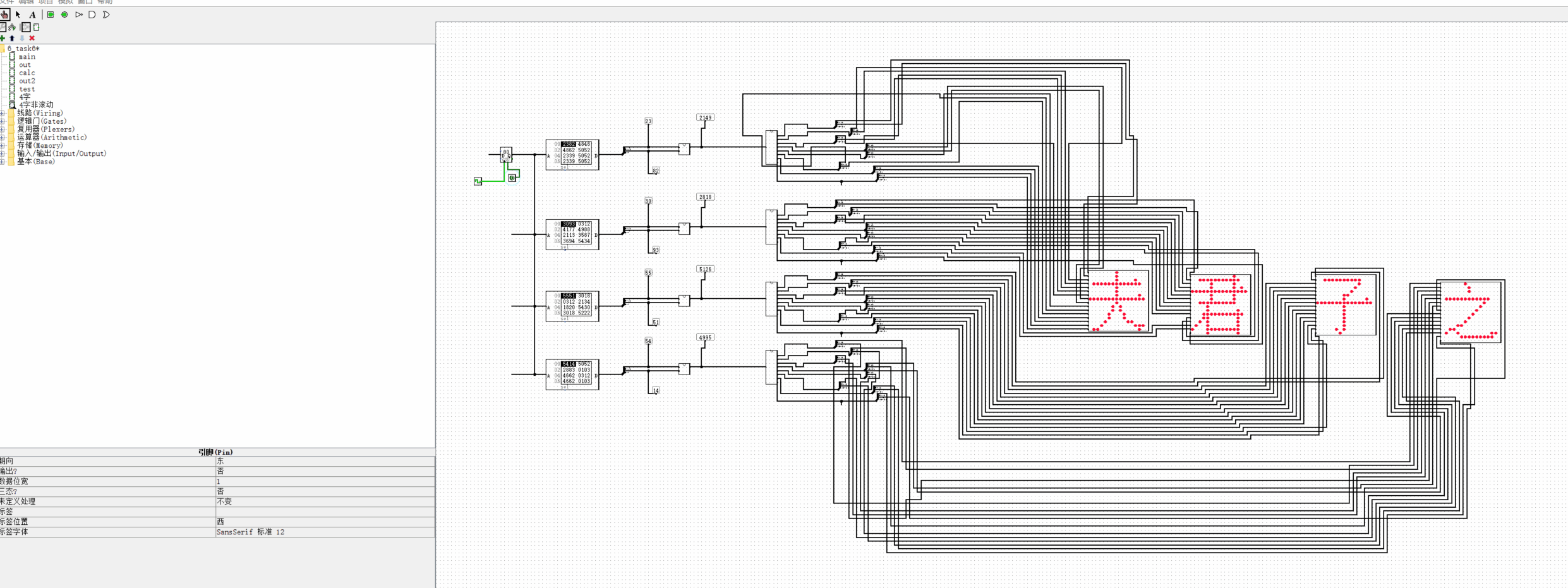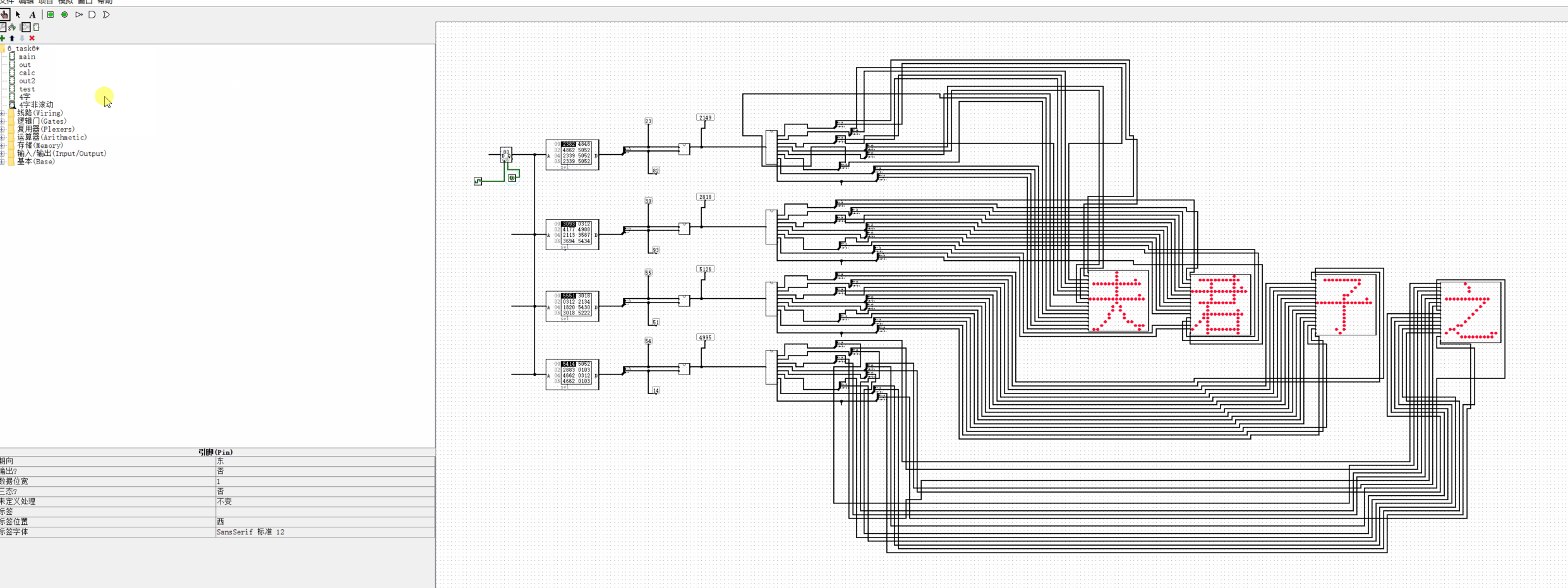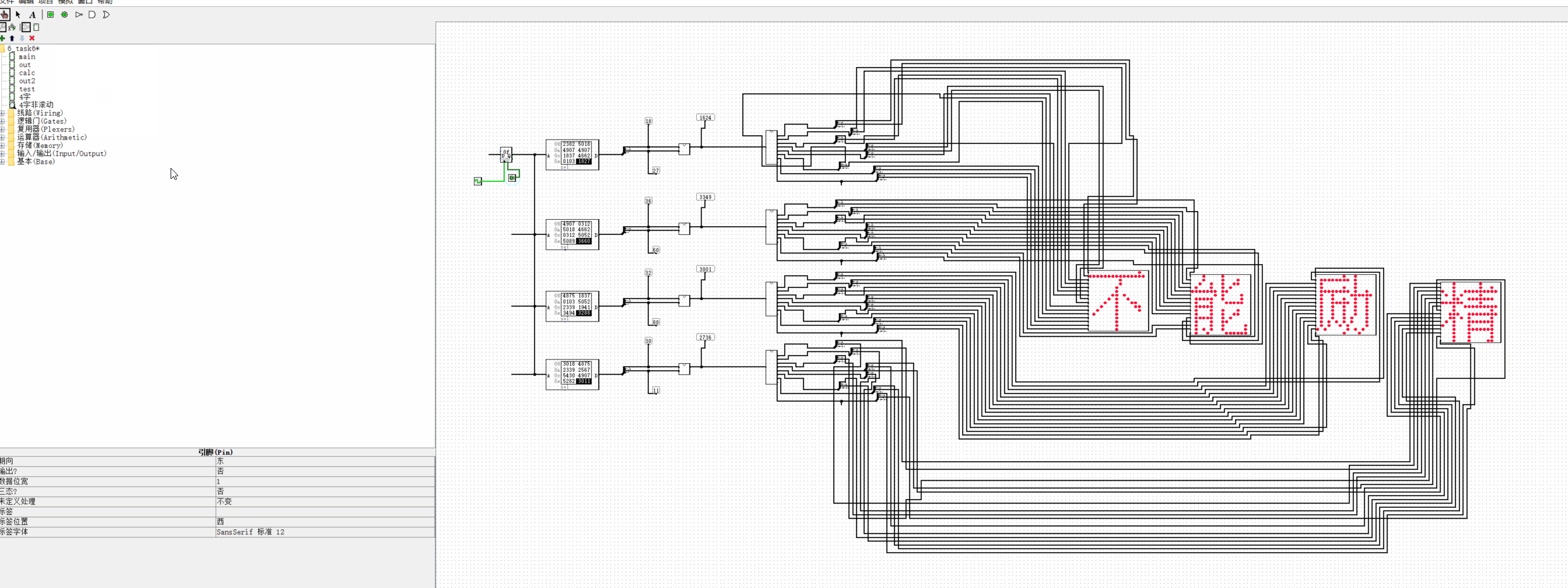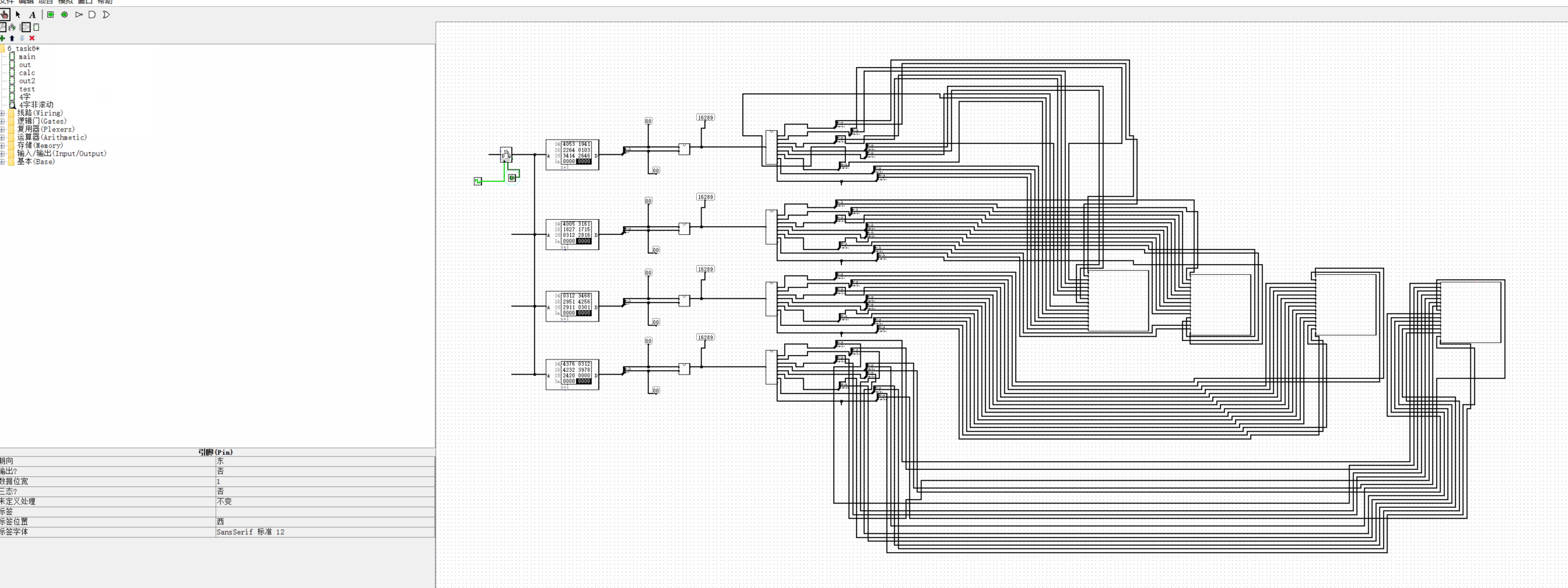
记得最后添加
XXX大学 XXX
姓。x名部分不放网上啦。
0xff:文件下载