大数据-笔记-1
文章地址:(可能更好的阅读体验)
- https://ovo.dayi.ink/2023/11/09/big%E6%95%B0%E6%8D%AE/
- https://www.cnblogs.com/rabbit-dayi/p/17822822.html
- https://type.dayiyi.top/index.php/archives/244/
- https://blog.dayi.ink/?p=93
- https://cmd.dayi.ink/-BShZBz_ThuNVoGepjYbsA (本文原始链接,打开速度可能偏慢)
1. 安装

2. 查看三台虚拟机IP

设置静态IP

3. 修改IPV4为manual

IP 地址如下:
gataway : 192.168.83.2
mask : 24
master: 192.168.83.10
slv1: 192.168.83.11
slv2: 192.168.83.12
3. 关闭防火墙
su
[输入密码:123456]
service iptable stop
service iptable status
===

slave1 slave2:


4.关闭防火墙自动运行
chkconfig iptables off
chkconfig --list | grep iptablesmaster:

slave1:

slave2:

5. 配置主机名
#hostname
vi /etc/sysconfig/network
cat /etc/sysconfig/network
hostname dayi-bigdata-master
hostname dayi-bigdata-salve-1
hostname dayi-bigdata-salve-2输入 i 进入编辑模式
输入 :wq 保存文件
发现已经做了)
master:

slave1:
![]
slave2:

6. IP 地址 HOSTNAME 绑定
vi /etc/hosts
192.168.83.XX master
192.168.83.xx slave1
192.168.83.xx slave2i : 进入编辑模式
:wq : 保存文件

master:

slave1:

slave2
chk1:
7. 修改windows的host
打开文件
路径打开这个:
C:\Windows\System32\drivers\etc\
C:\Windows\System32\drivers\etc\hosts
先复制到桌面,然后修改完再复制回去(真就同步,我先想出来的pvp写的PVP)


8. 配置远程SSH登录
哦,直接登录

但是不是限制密钥登录..登不进去呀
哦哦,可以直接登录,那没事了

添加三个主机之后

ok)

锟斤拷烫烫烫
问题解决:
chk:
- windows 的hosts文件
C:\Windows\System32\drivers\etc\ - 虚拟机的IP地址是否对应
三个节点窗口:
查看 -> 交互窗口 -> 右键底部的窗口,发送交互到所有标签
因为虚拟机里套虚拟机不好截图,菜单截不下来(

这个分割线没有用
我猜的
输入
ssh-keygen
生成RSA密钥:

复制公钥:

输入到虚拟机里的
.ssh/authorized_keys
9. 时钟同步
9.1 手动时间同步
su root
[输入密码:123456]
date #显示系统时间
hwclock --show #显示硬件时间
#如果时间不一样的话这样省事,直接NTP同步时间:
#设置硬件时钟调整为与本地时钟一致
timedatectl set-local-rtc 1
#设置时区为上海
timedatectl set-timezone Asia/Shanghai
ntpdate -u pool.ntp.org
date
## 手动同步
date -s 20230907
date -s 9:40
hwclock --systohc
显示系统时间

显示系统硬件时间:
(全是锟斤拷)
NTP同步时间
9.2 自动时间同步
下班
2023年9月13日14:09:57
时间同步
timedatectl set-local-rtc 1
#设置时区为上海
timedatectl set-timezone Asia/Shanghai
ntpdate -u ntp.aliyun.com
hwclock --systohc
9.3 配置自动时间同步
两个从节点
crontab -e
# 输入i进行输入模式
# ctrl+shift+v 粘贴
0 1 * * * /usr/sbin/ntpdate ntp.aliyun.com
# 输入:wq 保存10. 免密登录
#直接输入exit
# 或者
su dayi
10.1 设置SSH免密登录
ssh-keygen -t rsa
#然后回车3次就行了
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
cat ~/.ssh/authorized_keys
我觉得这个公钥有点用:(应该没啥用了)ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA6yR468UQBZ/9KSG71FD0UVlv9N0I6q2RfA94yLT7uGhja9vzBJSP9mDg8RF8+Z6p5+katfYE7YLzjtLNMtC5lTjkwW8WHFyCGUP0QEcAIH0ZdDVn3nwHG9k+b2XfpLNKOieWYqUoixRSzIecUd5iq3WDe4dUjgBmGhfouo+FtQob/q8OOg2iJszl86ad8dE9W2BRS3VU5q6/OZmPp8uJcfXAl4/bHJq56+FNPSwk9b+umAsiH+bqeVCkW6JJd/Tw7DGkhYACGxleF5onBtiLKwbMZ+RanWiFm9AZqod86rcmZ9IPYaWf/QXgyun5vrNBBgBT+a8CBsRoBpFk0X7CCw== dayi@dayi-bigdata-master
ssh-copy-id dayi-bigdata-slave-1
ssh-copy-id dayi-bigdata-slave-2
10.2 测试是否免密登录
ssh dayi-bigdata-slave-1
# 退出 exit 或者 ctrl+d
ssh dayi-bigdata-slave-2
# 退出 exit 或者 ctrl+d
11. 安装JDK(普通用户)
新建文件夹
cd ~
mkdir -p ~/resources
cd ~/resources复制文件
sftp://dayi-bigdata-master
sftp://dayi-bigdata-slave-1
sftp://dayi-bigdata-slave-2


查看下当前的文件
ls
[dayi@HOSTNAME=dayi-bigdata-slave-2 resources]$ ls
jdk-7u71-linux-x64.gz
[dayi@HOSTNAME=dayi-bigdata-slave-2 resources]$
解压
tar -zxvf jdk-7u71-linux-x64.gz
# 重命名
mv jdk1.7.0_71 jdk11.1 配置环境变量
# (可选,出错请忽略)按老师目录移动文件
mv ~/Home/resources ~/resources
vim ~/.bash_profile
#按 i 输入
export JAVA_HOME=~/resources/jdk
export PATH=.:$JAVA_HOME/bin/:$PATH
#input: :wq (保存)
source .bash_profile11.2 验证JDK安装成功
java -version
12. 安装hadoop(master 普通用户)
只做主节点。
tar -zxvf hadoop-2.6.4.tar.gz
mv hadoop-2.6.4 hadoop编辑bash配置 文件
# 记得在普通用户下
vim ~/.bash_profile
# i 输入
# 编辑模式下ctrl+shift+v
export HADOOP_HOME=~/resources/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
#:wq保存文件
np++连接
- 打开notepad++

输入配置文件
点这个
然后到这里来:
/home/dayi/resoureces/hadoop/etc/hadoop

修改hadoop-env.sh
hadoop-env.sh 25 行
export JAVA_HOME=~/resources/jdk
修改 yarn-env.sh
yarn-env.sh
- 23 行
export JAVA_HOME=~/resources/jdk
修改 core-site.xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wg/resources/hadoopdata</value>
</property>
</configuration>
新建data文件夹
# 记得自己改
mkdir -p /home/dayi/resources/hadoopdata修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
ctrl+s
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
修改mapred-site.xml
- 打开
mapred-site.xml.template - 新建文件:

- 输入内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
打开slaves
添加
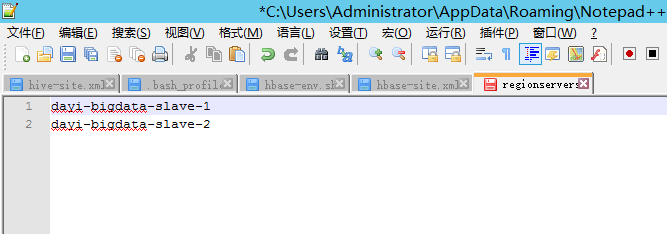
slave1
slave2
将配置好点hadoop发送到从节点
cd ~
cd resources
scp -r
scp -r hadoop dayi-bigdata-slave-1:~/resources/hadoop/
scp -r hadoop dayi-bigdata-slave-2:~/resources/hadoop/

13.启动hadoop
- 格式化文件系统(master,普通用户
hadoop namenode -format

- 启动hadoop
cd ~/resources/hadoop/sbin/
./start-all.sh
~/resources/hadoop/sbin/./start-all.sh

- check
jps





13.1 验证
#启动
~/resources/hadoop/sbin/./start-all.sh13.2 修复
~/resources/hadoop/sbin/./stop-all.sh
rm -rf ~/resources/hadoopdata
rm -rf ~/resources/hadoop/logs
hadoop namenode -format
~/resources/hadoop/sbin/./start-all.sh结果:
14 HDFS
先保证你的节点有两个以上哦
- 浏览文件
hadoop fs -ls /好像没什么东西

这里好像也可以看:
http://master:50070/explorer.html#/

- 创建目录
# 创建目录
hadoop fs -mkdir /ovo
hadoop fs -mkdir /a
# 查看目录/
hadoop fs -ls /
主页查看文件
- 上传文件?
1) 本地新建一个文件
也可以直接图形界面去干
```bash
cd ~
mkdir b
ls -alh b
cd b
echo ovo>>ovo.txt
# i 输入 esc->:wq 保存
vi test
```
查看目录和文件:
```bash
ls -alh
cat test
```
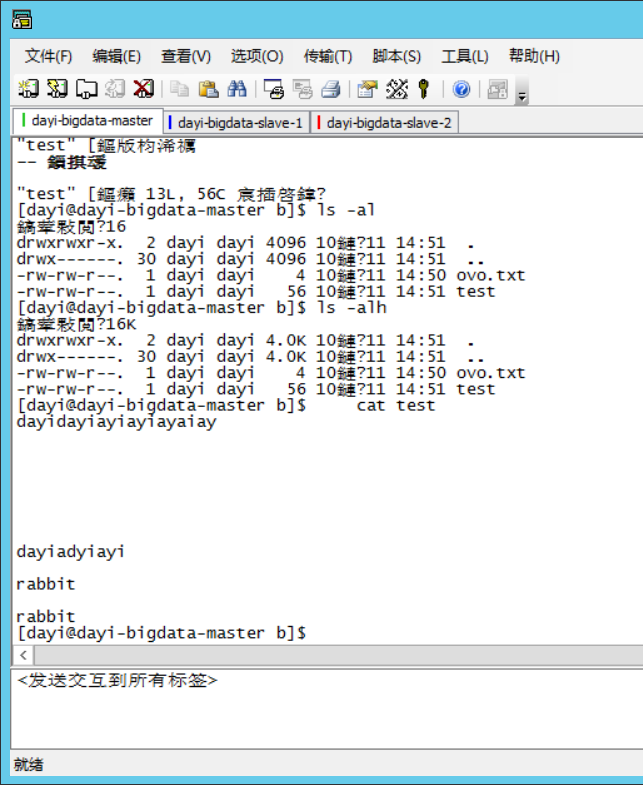
2) 将test上传到文件系统
cd ~/b
hadoop fs -put test /a
hadoop fs -ls /a
#或者主页打开


- 查看文件内容
hadoop fs -cat /a/test
hadoop fs -text /a/text

- 下载文件
hadoop fs -get /a/test test1
ls -alh
cat test1
- 修改文件权限
hadoop fs -ls /a
hadoop fs -ls /
hadoop fs -chmod +? 

-rw-r--r--
- 文件/目录
rwx : read write exce(执行)
rw- : 用户权限 (u)
r-- : 组权限 (g)
r-- : 其他人权限 (o)
增加执行权限:
hadoop fs -chmod u+x /a/test
hadoop fs -ls /a
组权限+wx
other权限+wx
hadoop fs -chmod o+x /a/test
hadoop fs -chmod g+x /a/test
hadoop fs -ls /a
去除所有人的执行权限
hadoop fs -chmod a-x /a/test
hadoop fs -ls /a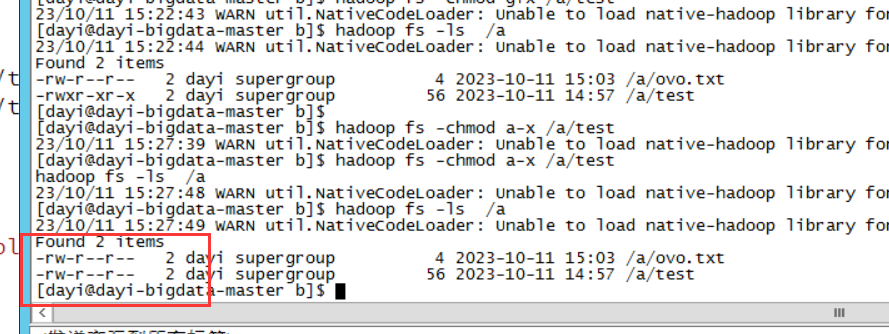
数字:
000
rwx
自由组合,二进制转十进制
比如全部权限
111 = 2^0+2^1+2^2=1+2+4=7
rwx
权限
hadoop fs -chmod 644 /a/test
#很危险的操作哦)容易被黑掉
hadoop fs -chmod 777 /a/test
hadoop fs -ls /a
hadoop fs -chmod 644 /a/test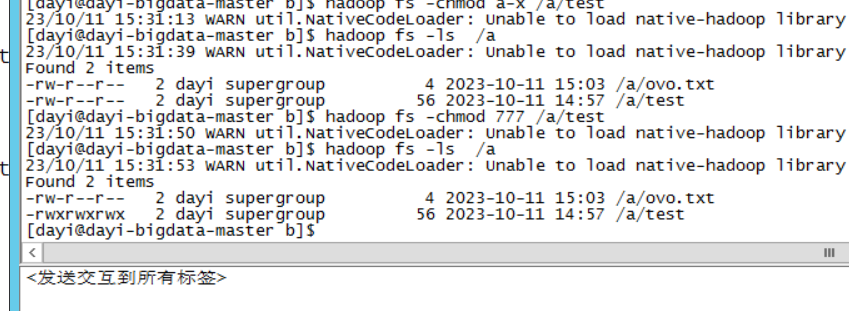
- 删除文件
hadoop fs -rm /a/test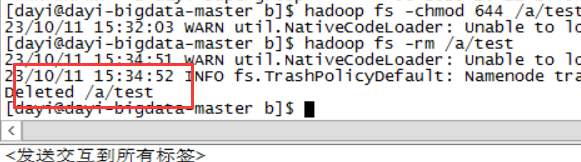
- 删除目录
hadoop fs -rm -r /a
hadoop fs -ls /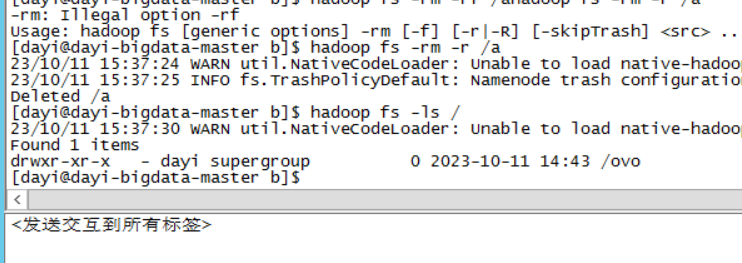
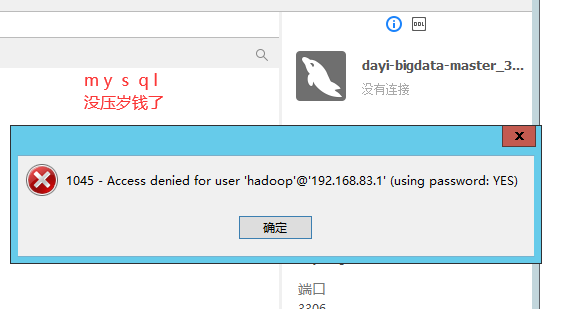
15. mysql安装?
- 新建mydb文件
普通用户
mkdir ~/resources/mydb- 复制文件,把文件粘贴进去
能直接粘贴到虚拟机就不用这个
这里软件是filezila
如何连接:
- 检查系统里是否有自带的mysql
su
rpm -qa | grep -i mysql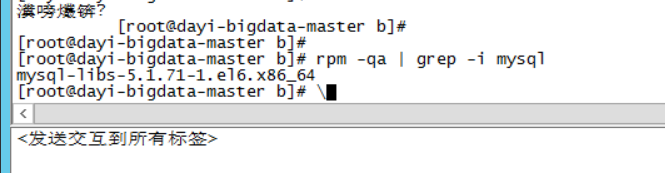
有一个诶
- 有的话就删除
建议打个快照先
rpm -e mysql-libs-5.1.71-1.el6.x86_64 --nodeps
#然后看看还有没有
rpm -qa | grep -i mysql
- 安装4个文件
common , libs , client, server
#(在普通用户下)
su dayi(按你用户名)
cd ~
su
cd resources/mydb
ls -al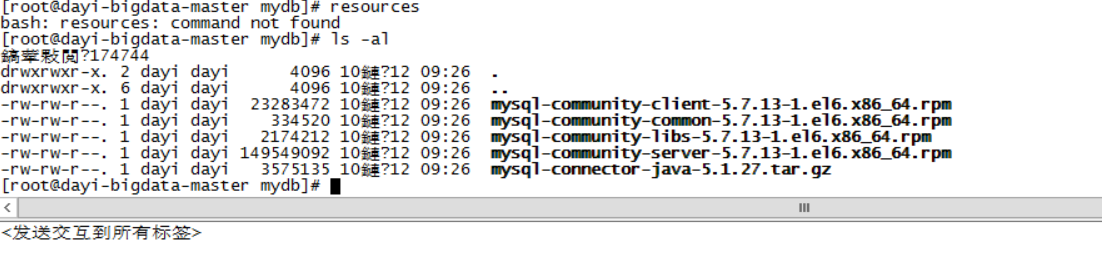
安装:
rpm -ivh mysql-community-common-5.7.13-1.el6.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.13-1.el6.x86_64.rpm
rpm -ivh mysql-community-client-5.7.13-1.el6.x86_64.rpm
rpm -ivh mysql-community-server-5.7.13-1.el6.x86_64.rpm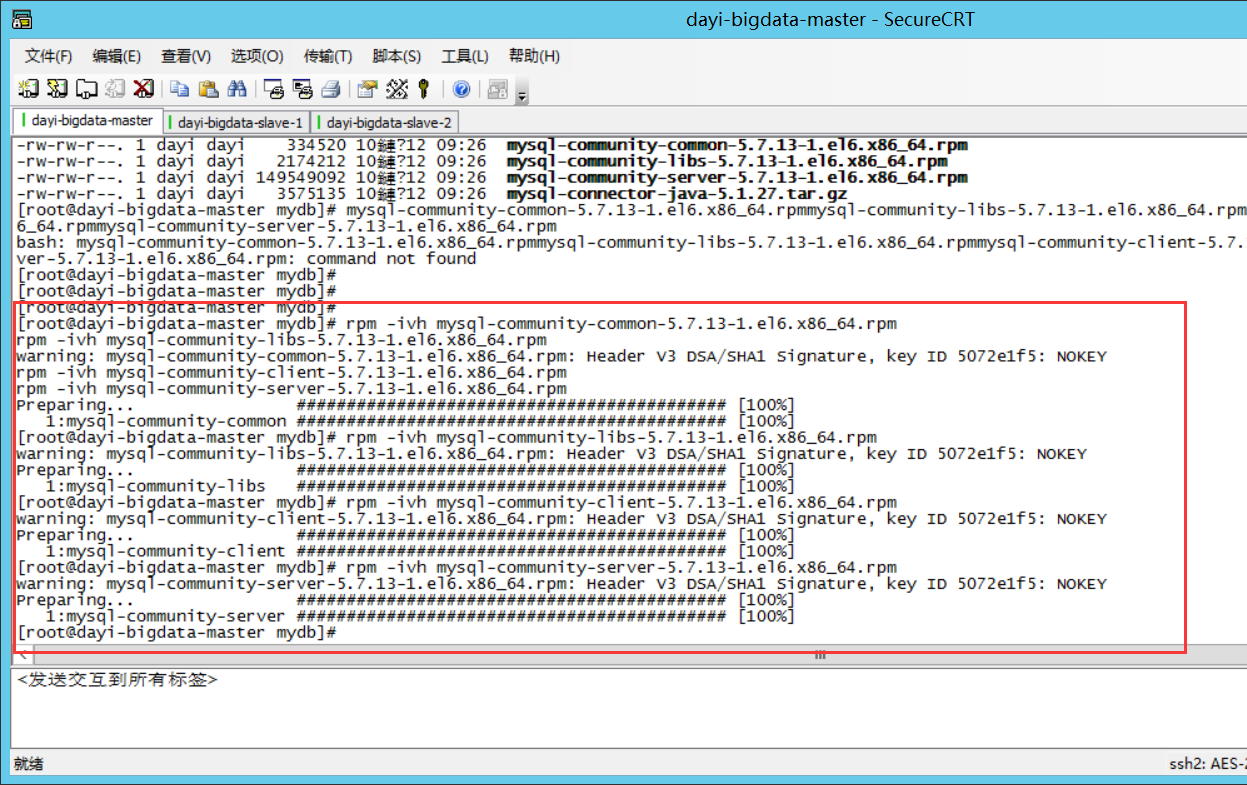
- 启动server
service mysqld start 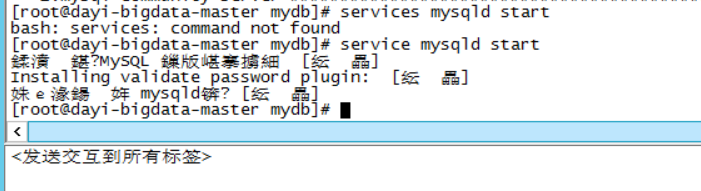
修改mysql默认密码
service mysqld start
sudo cat /var/log/mysqld.log | grep 'temporary password'
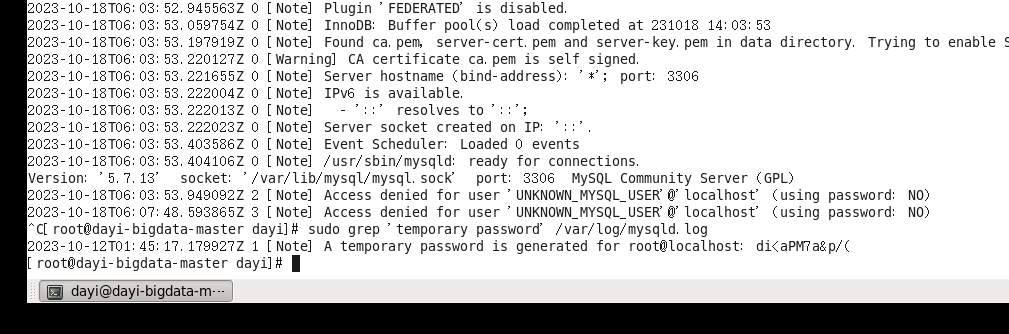
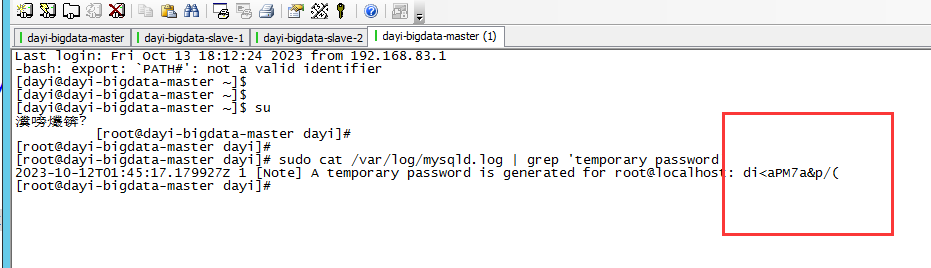
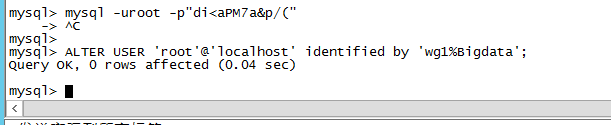
mysql -uroot -p"di<aPM7a&p/("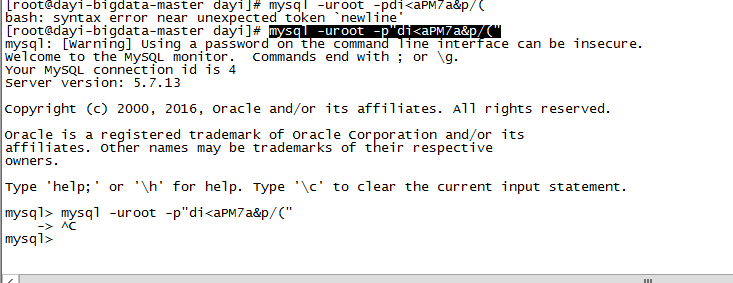
修改密码:
用户名:root
密码:wg1%Bigdata
ALTER USER 'root'@'localhost' identified by 'wg1%Bigdata'; OK 就可以
mysql中创建用户
用户名: hadoop
密码: hadoop1%Bigdata
Grant all on *.* to 'hadoop'@'%' identified by 'hadoop1%Bigdata';
grant all on *.* to hadoop@'localhost' identified by 'hadoop1%Bigdata';
grant all on *.* to hadoop@'master' identified by 'hadoop1%Bigdata';
flush privileges;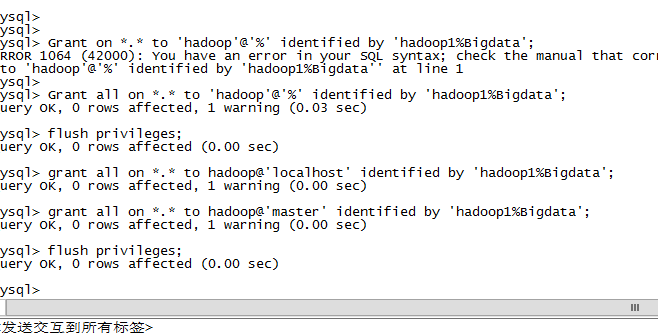
尝试登录
quit;
su dayi
mysql -uhadoop -p"hadoop1%Bigdata"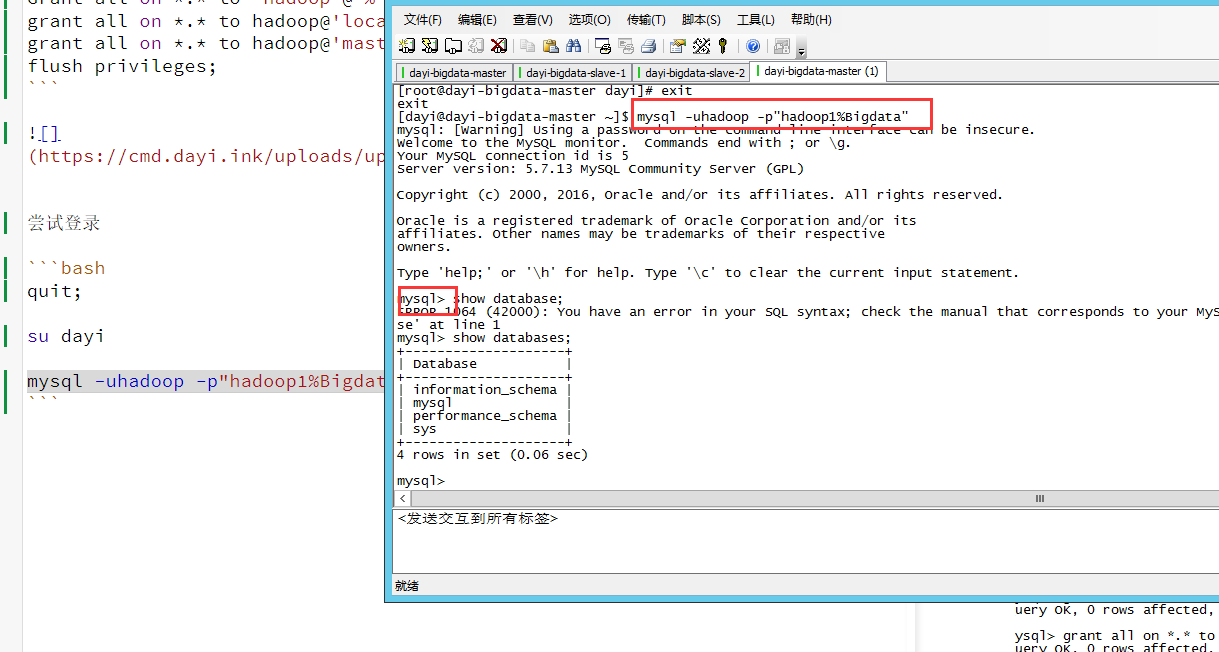
MYSQL数据库里创建hive元数据库,叫hive1
查看当前数据库
show databases;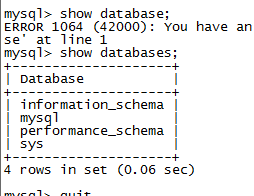
创建数据库
create database hive1;
show databases;
quit;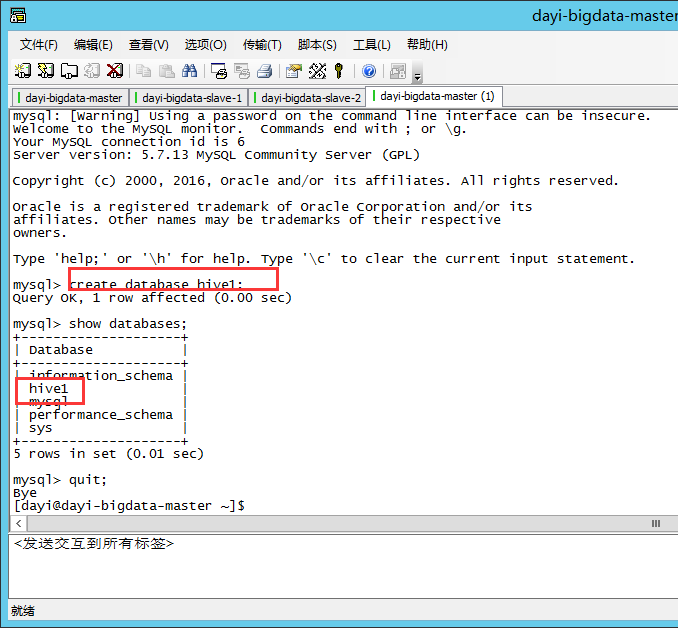
16. 安装hive
1.复制hive文件到resources
2.解压缩
#进入目录
cd ~/resources
# 解压缩
tar -zxvf apache-hive-1.2.1-bin.tar.gz
# 重命名(移动)
mv apache-hive-1.2.1-bin hive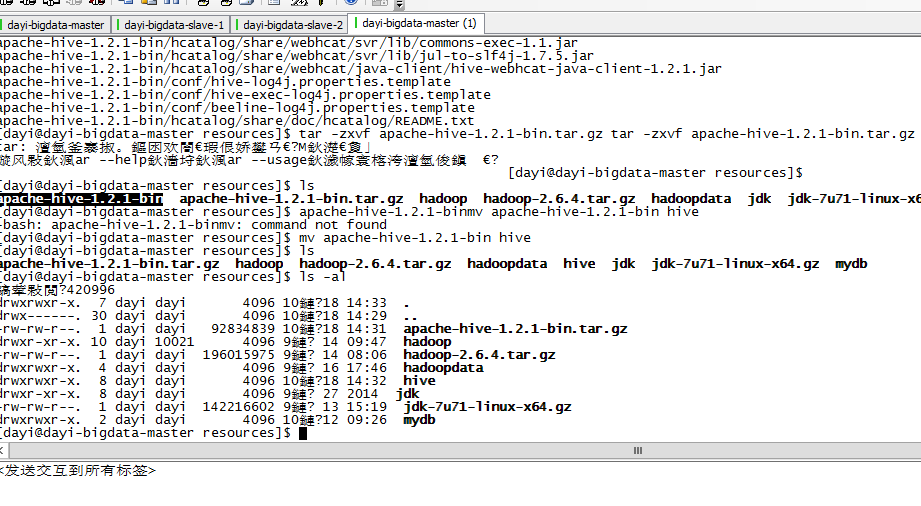
3. NPP改配置文件
连接:
打开目录:~/resources/hive/conf
新建文件,右键文件夹hive-site.xml
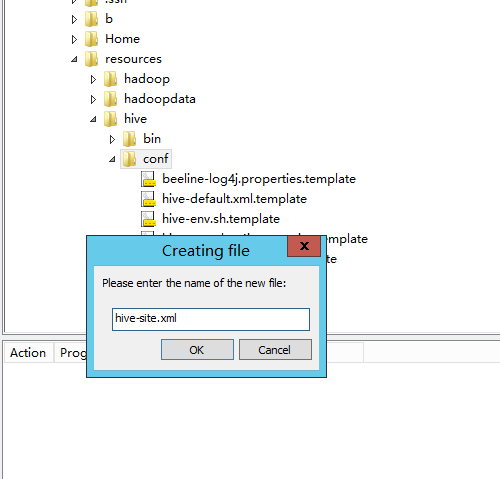
内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive1?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop1%Bigdata</value>
</property>
</configuration>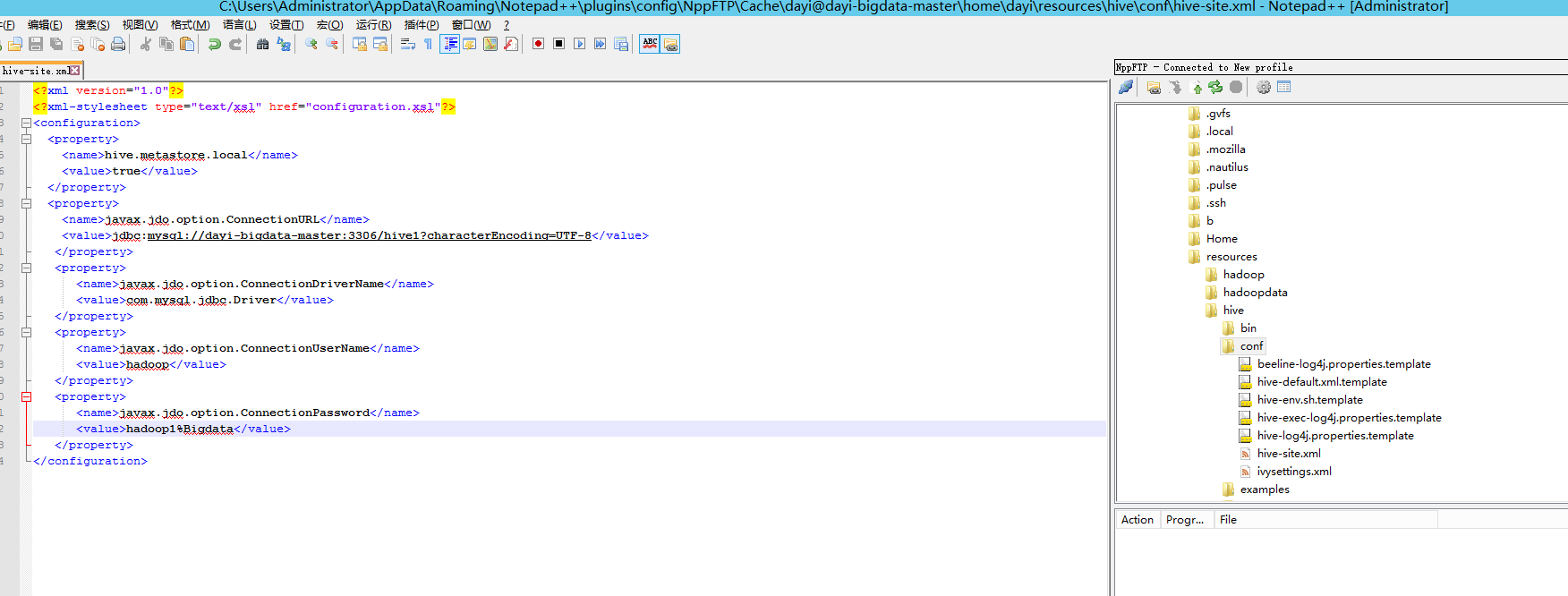
如果你的主机名不一样记得改这行:jdbc:mysql://master:3306/hive1?characterEncoding=UTF-8
jdbc:mysql://master:3306/hive1?characterEncoding=UTF-8
driver host port database_name
hadoop 用户名
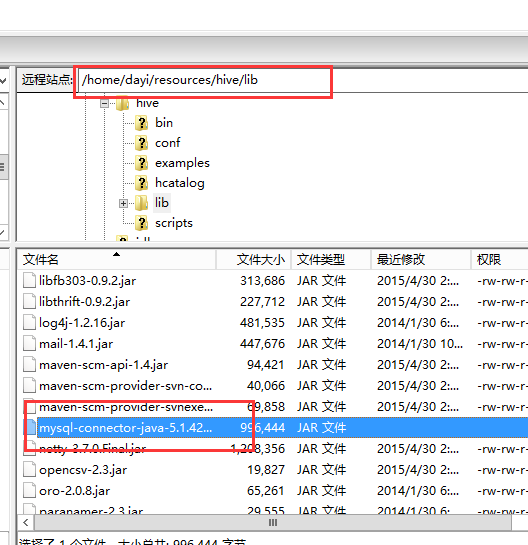
hadoop1%Bigdata 密码4. 复制驱动
mysql-connector-java-5.1.42-bin.jar -> ~/resources/hive/lib
5.配置bash
配置环境变量
- npp
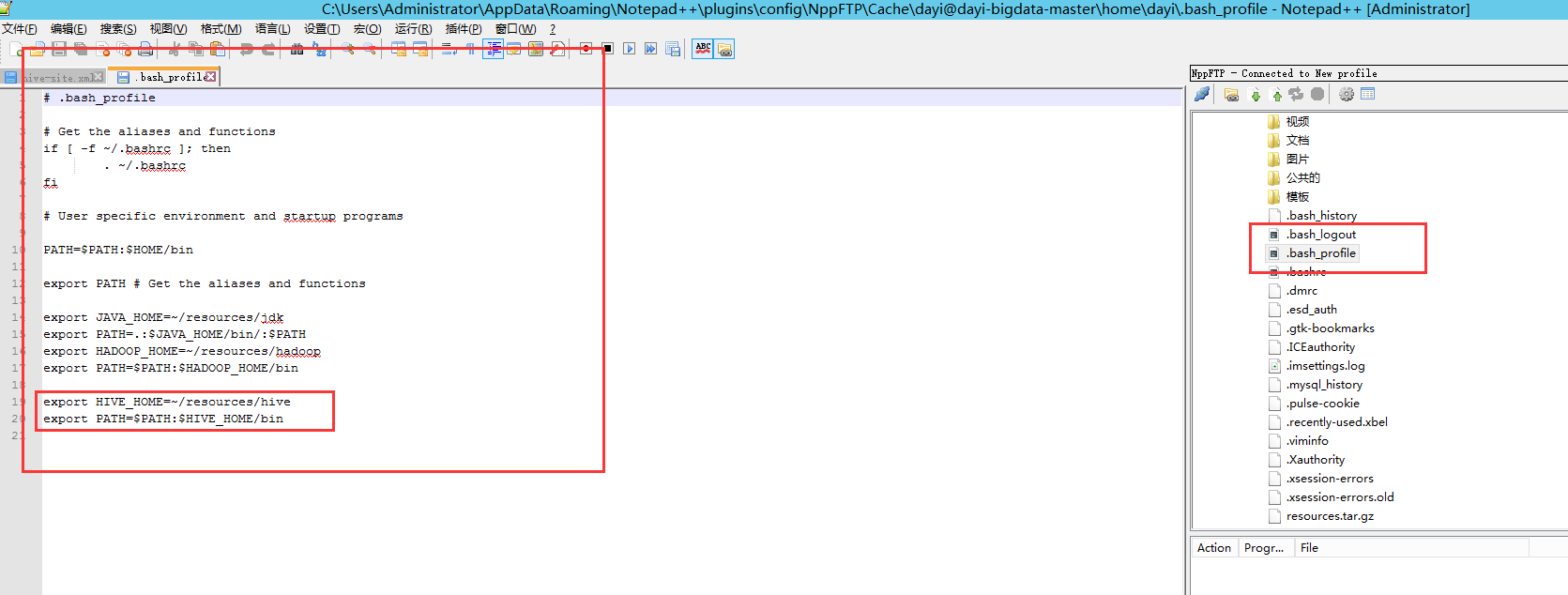
vim ~/.bash_profile
#添加这两行
export HIVE_HOME=~/resources/hive
export PATH=$PATH:$HIVE_HOME/bin
# 重载配置文件
source ~/.bash_profile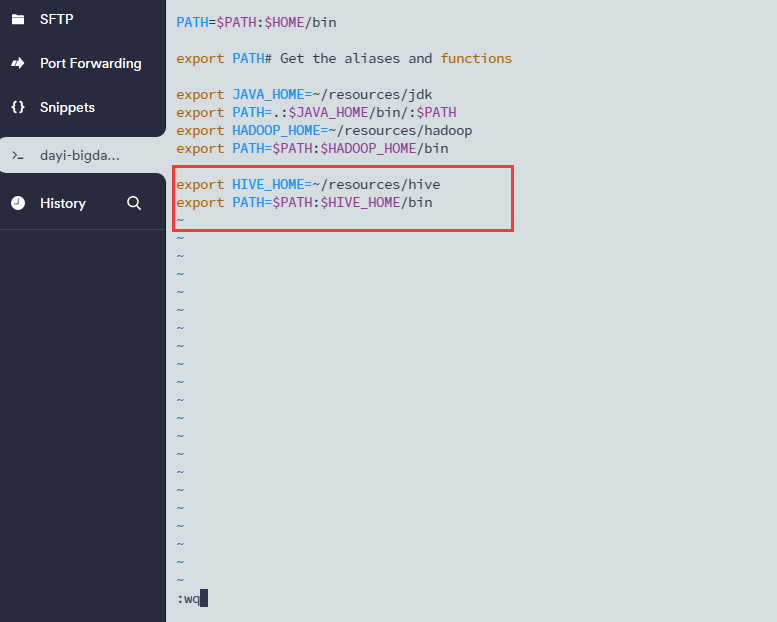
然后查看hive版本,如果能查看就说明环境目录成功了
hive --version
搞得和预言家一样
6. 替换文件
rm ~/resources/hadoop/share/hadoop/yarn/lib/jline-0.9.94.jar
cp ~/resources/hive/lib/jline-2.12.jar ~/resources/hadoop/share/hadoop/yarn/lib/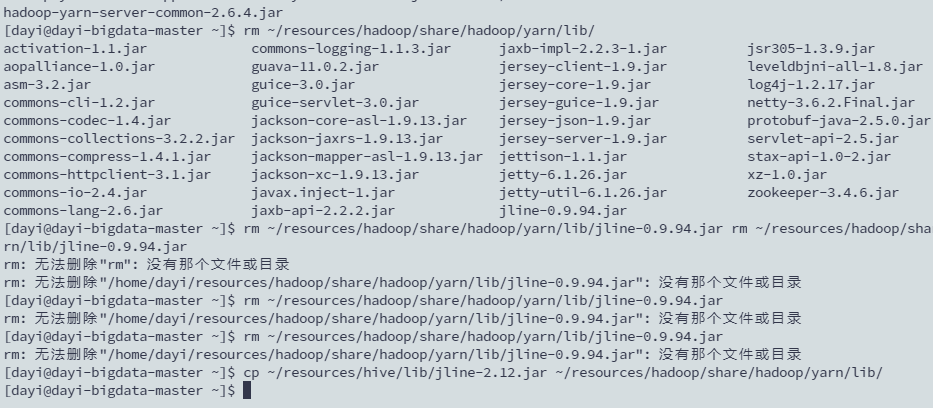
7. 启动hive
#1.下载原神(hadoop)
~/resources/hadoop/sbin/./start-all.sh
#2. 安装原神(mysqld)
service mysqld start
#3.启动原神
hive

原神:
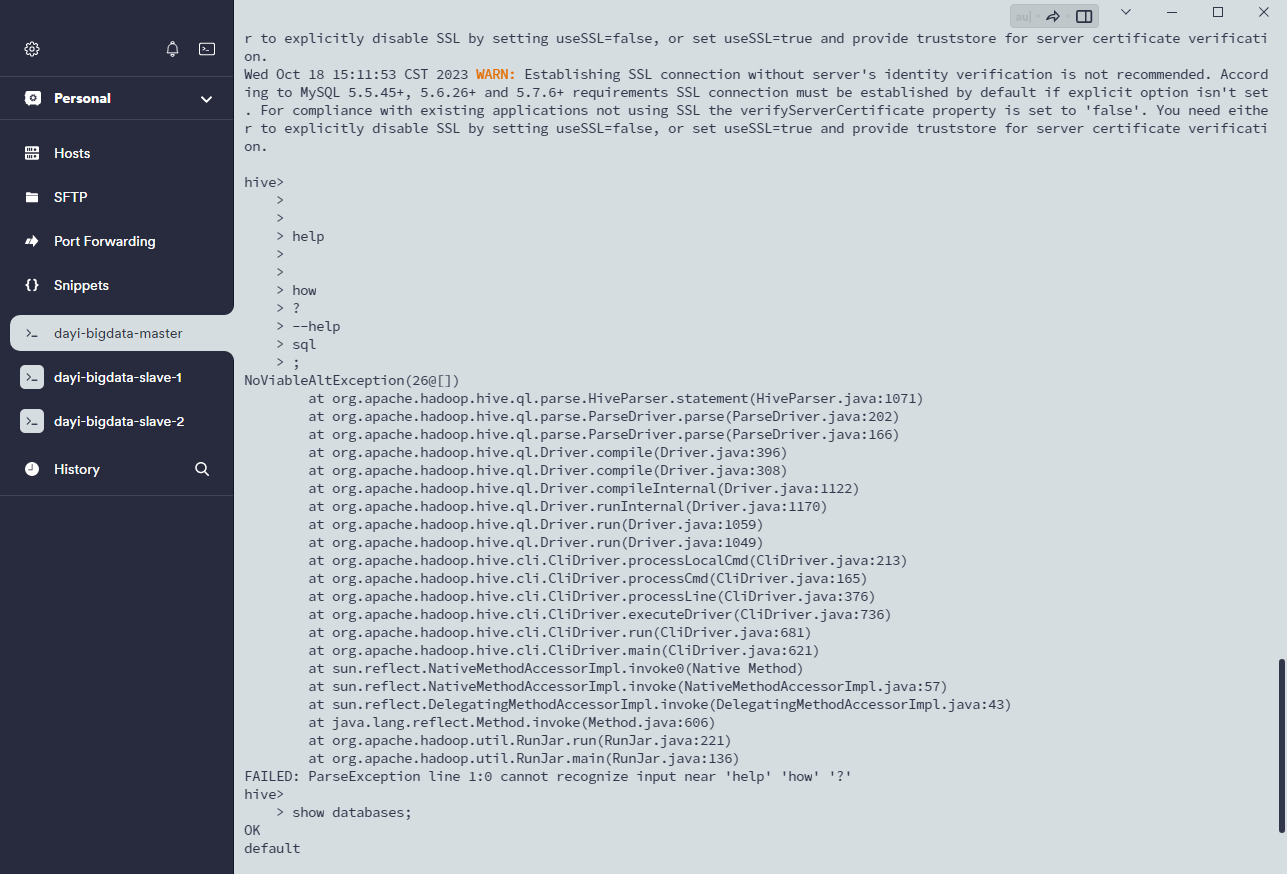
8.启动
~/resources/hadoop/sbin/./start-all.sh
service mysqld start
hive
CRT 调整:
17.hive应用
hive>quit;1. 新建文件
cd ~
mkdir cc
cd cc
vi stui 输入 ESC+:wq保存
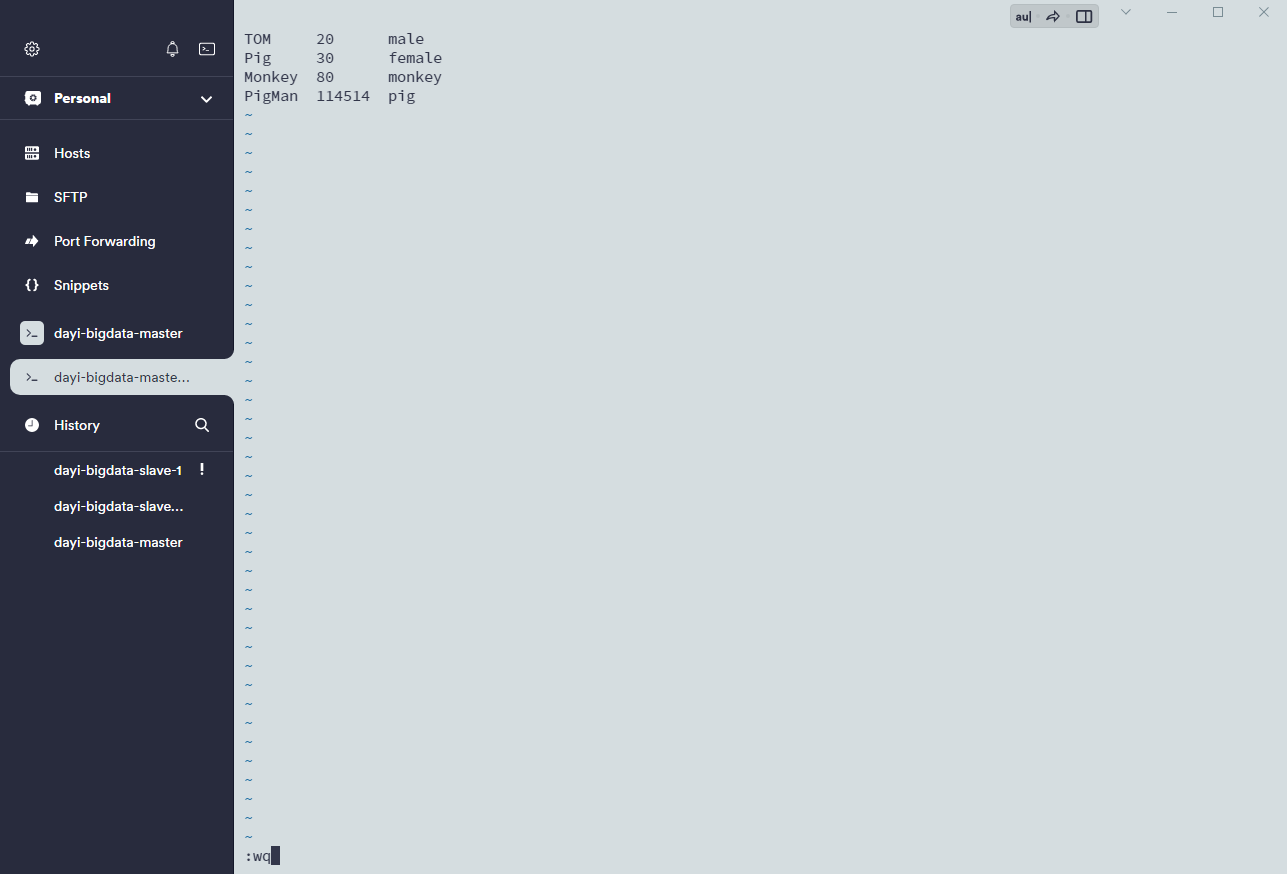
查看文件
cat stu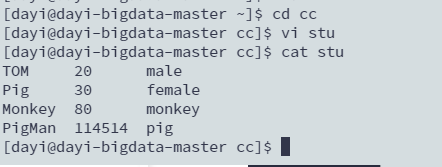
2.启动hive
hive命令:
查看数据库
show databases;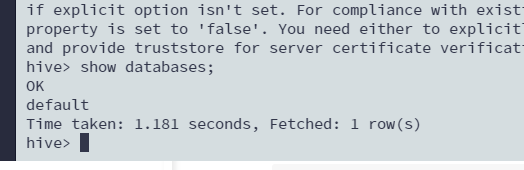
创建数据库
create database studb; show databases;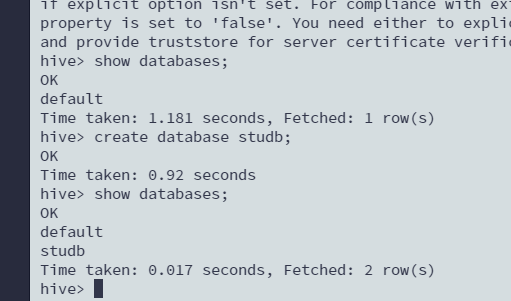
切换数据库
use studb;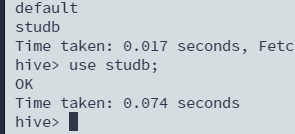
查看当前数据库里的表
show tables;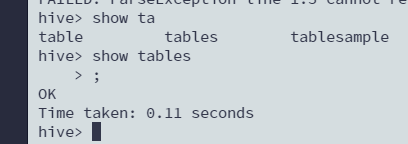
创建表
\t来区分列create table if not exists stu (name string,age int,sex string) row format delimited fields terminated by '\t'; show tables;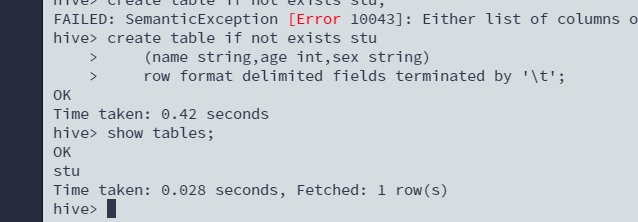
查看文件:
http://master:50070/explorer.html#/user/hive/warehouse/studb.db/
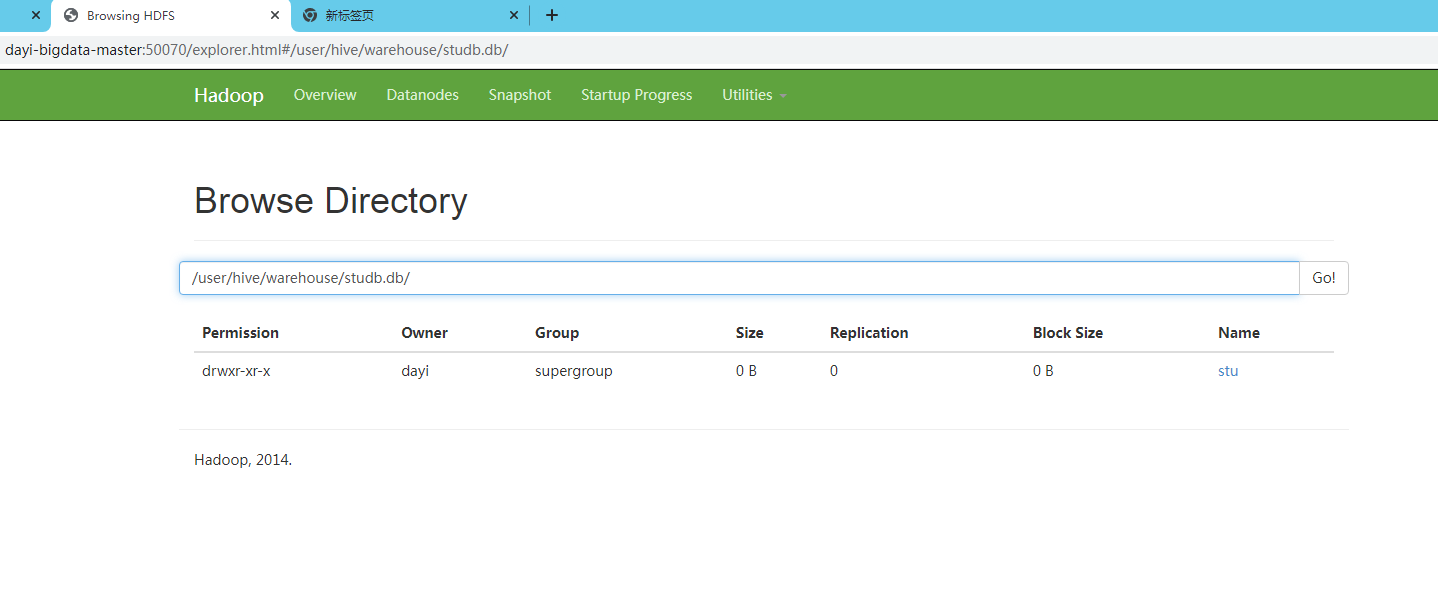
查看表的创建信息等
show create table stu;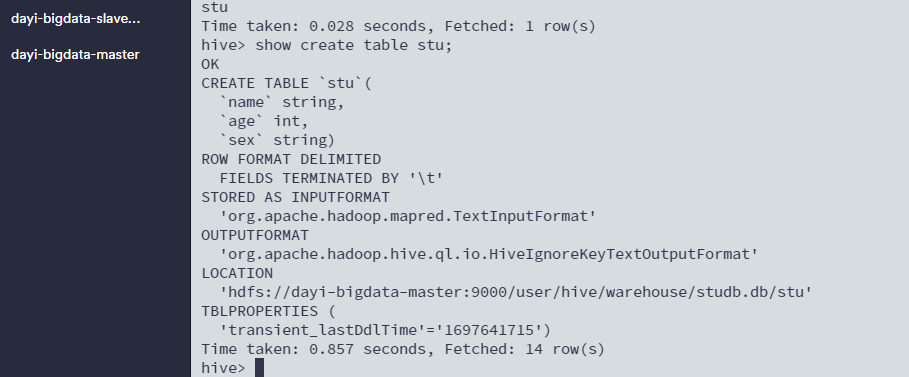
查看表结构
desc stu;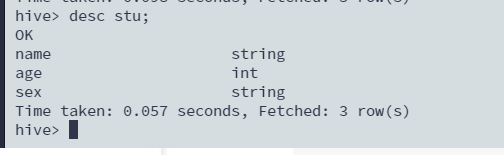
3. 加载数据
在hive下
从文件加载数据
load data local inpath '/home/dayi/cc/stu' into table stu;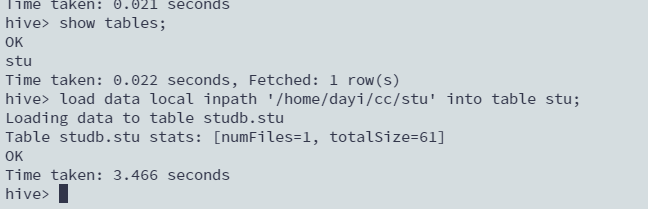
查询表
select * from stu;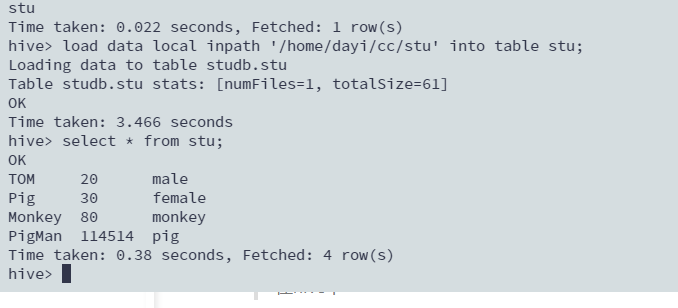
删除表
drop table stu;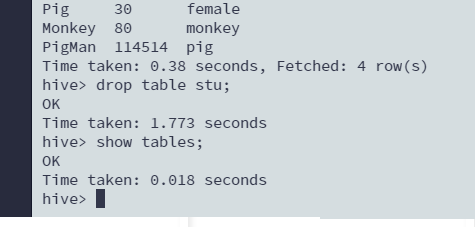
删库跑路
database没有表,为空
drop database studb;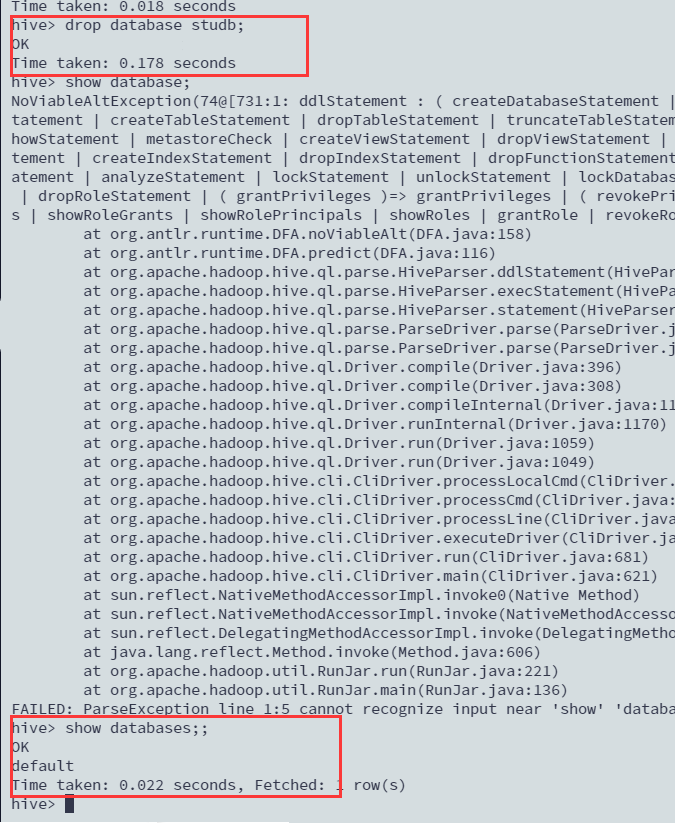
有表的情况下
drop database studb cascade;
4. 大数据分析-hive应用2
搜狗
ts 搜索时间
uid 用户id
kw 用户搜索的关键字
rank 搜索结果排序
orders 点击次数
url 访问的路径创建
create database sogoudb;
show databases;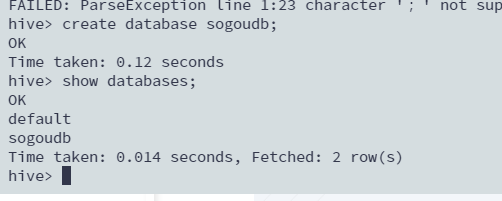
使用数据库
use sogoudb;创建外部表
create external table if not exists sogou
(ts string,uid string,kw string,rank int,orders int,url string)
row format delimited fields terminated by '\t'
location '/s1/sogoudata';
查看表
show tables;
desc sogou;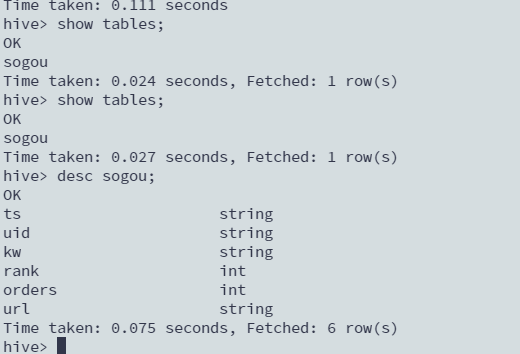
加载数据方式2
把这个500M文件(sogou.500w.utf8)塞到cc目录(~/cc)
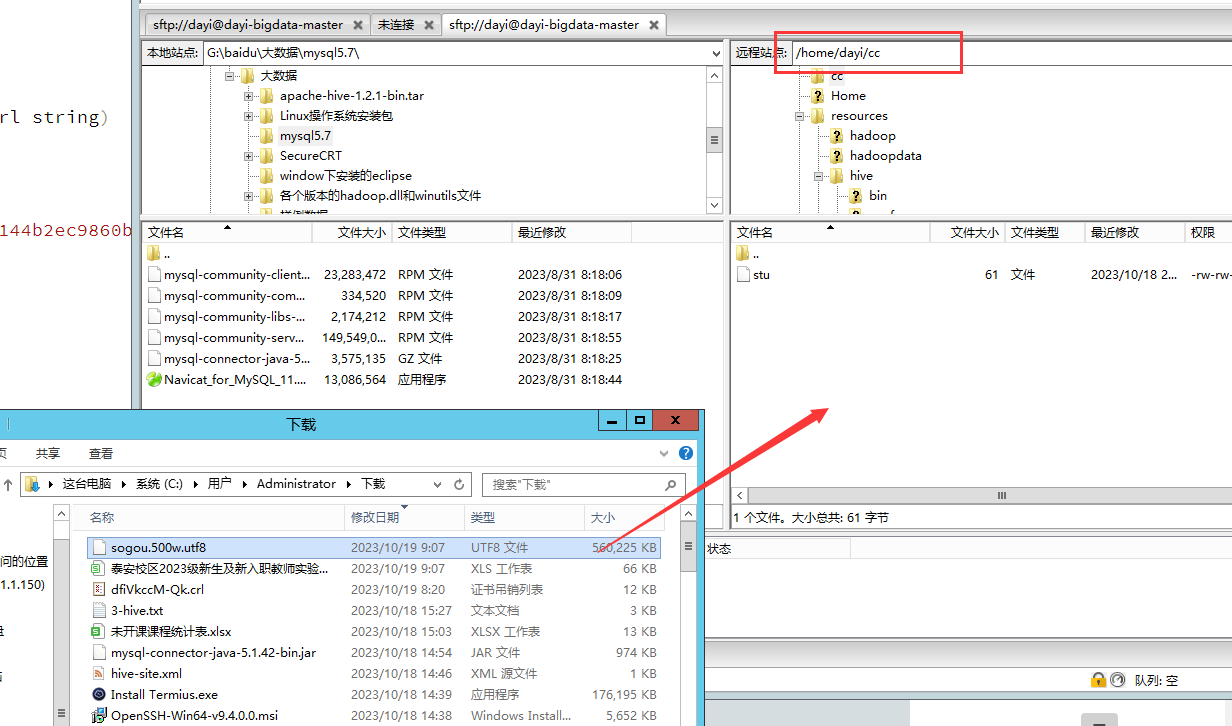
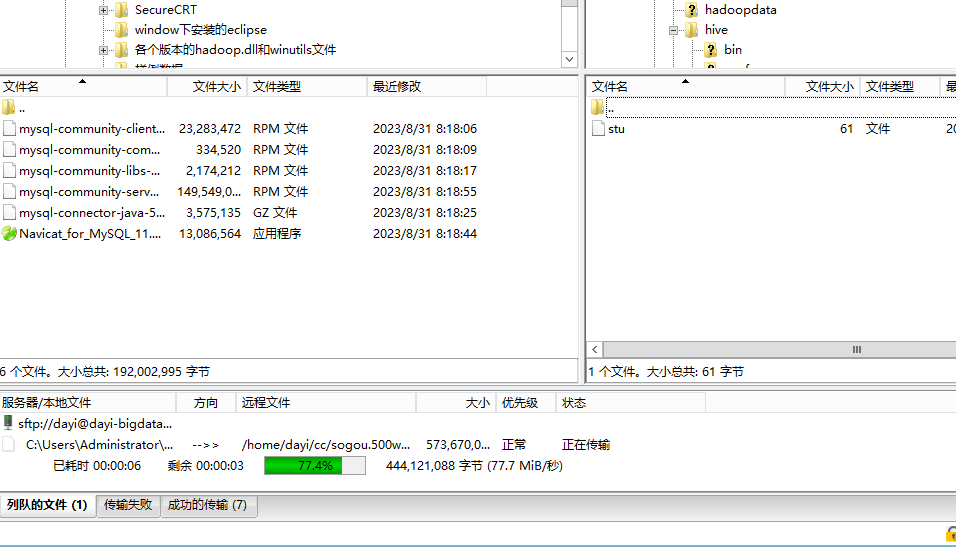
查看文件
cd ~/cc
ls -alh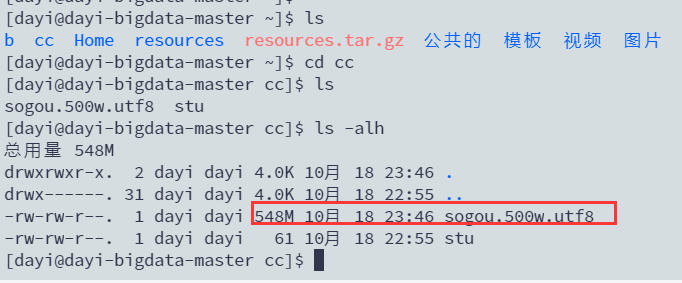
上传文件
#上传文件(好慢)
hadoop fs -put sogou.500w.utf8 /s1/sogoudata
#查看文件
hadoop fs -ls /s1/sogoudata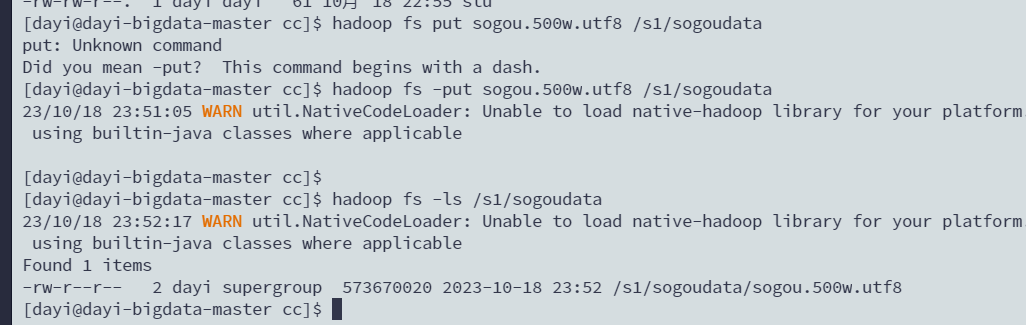
http://dayi-bigdata-master:50070/explorer.html#/s1/sogoudata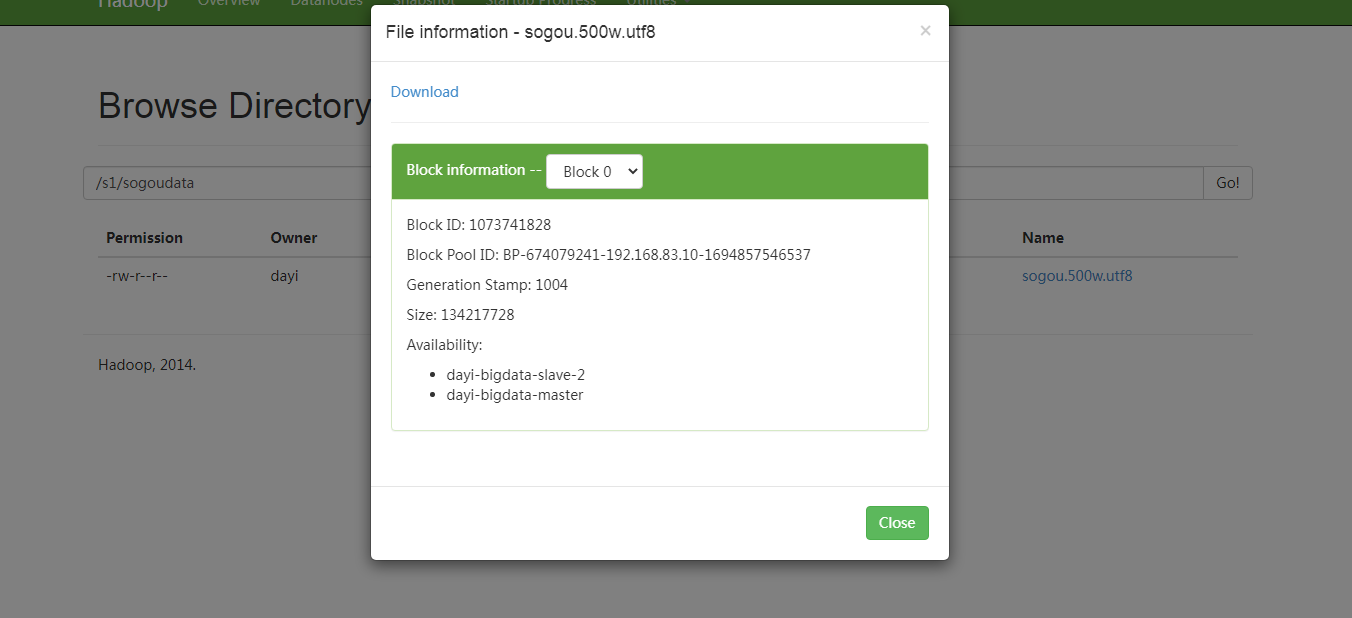
进入hive-导入
在hive里
use sogoudb;查询记录-前三条
select * from sogou limit 3;

查询表里总共多少记录
select count(*) from sogou;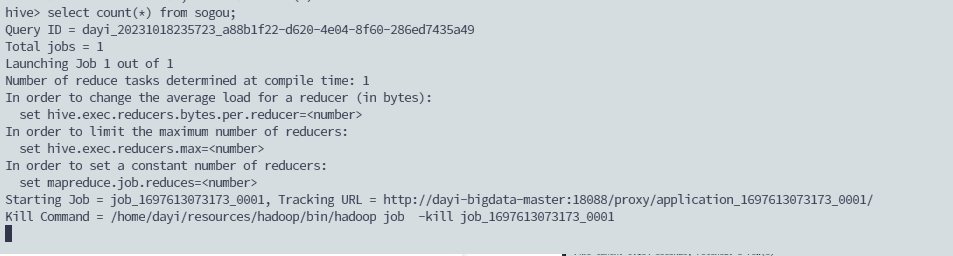
超级慢
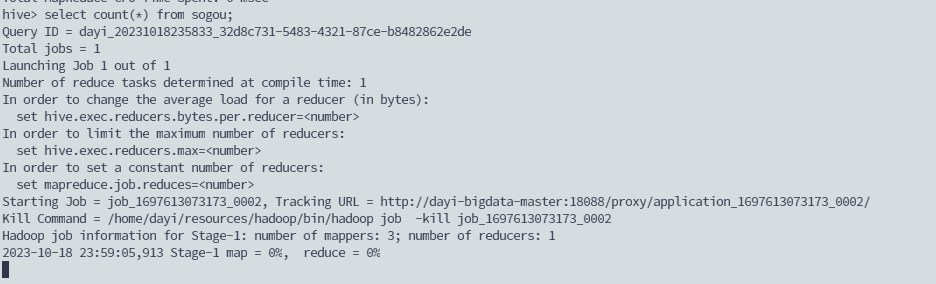

193秒: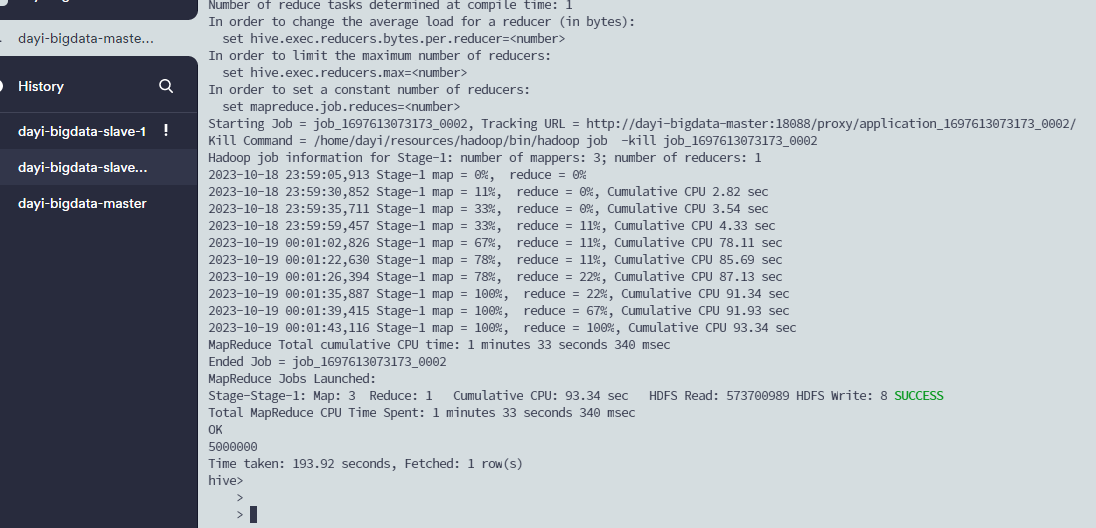
查询UID总数
select count(distinct(uid)) from sogou;还没执行完
177秒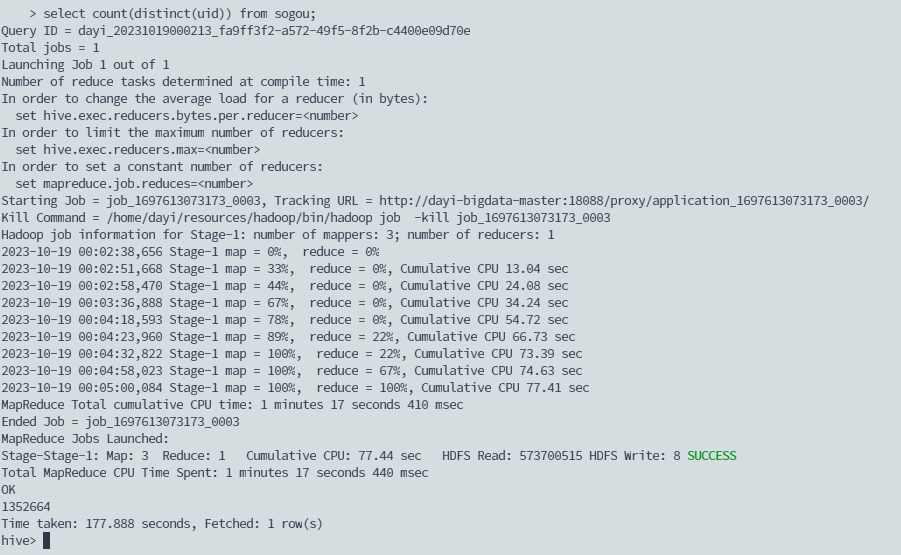
select count(uid) from sogou
group by uid;
出来了: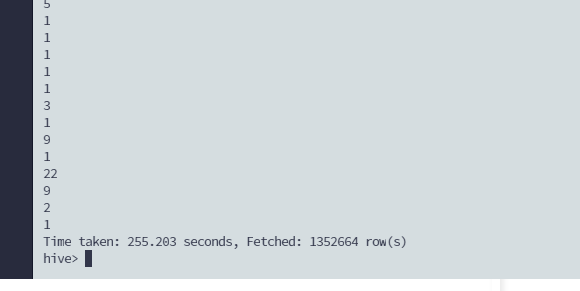
统计用户平均查询次数
$平均次数=总次数/用户个数$
建立临时表:
表a
| uid | cnt |
|---|---|
| a | 10 |
| b | 20 |
总次数 = sum(a.cnt)
用户个数 = count(a.uid)
临时表a
select uid,count(*) as cnt
from sogou
group by uid;总表:
select sum(a.cnt)/count(a.uid) from
(select uid,count(*) as cnt
from sogou
group by uid)as a;开炮:

好慢: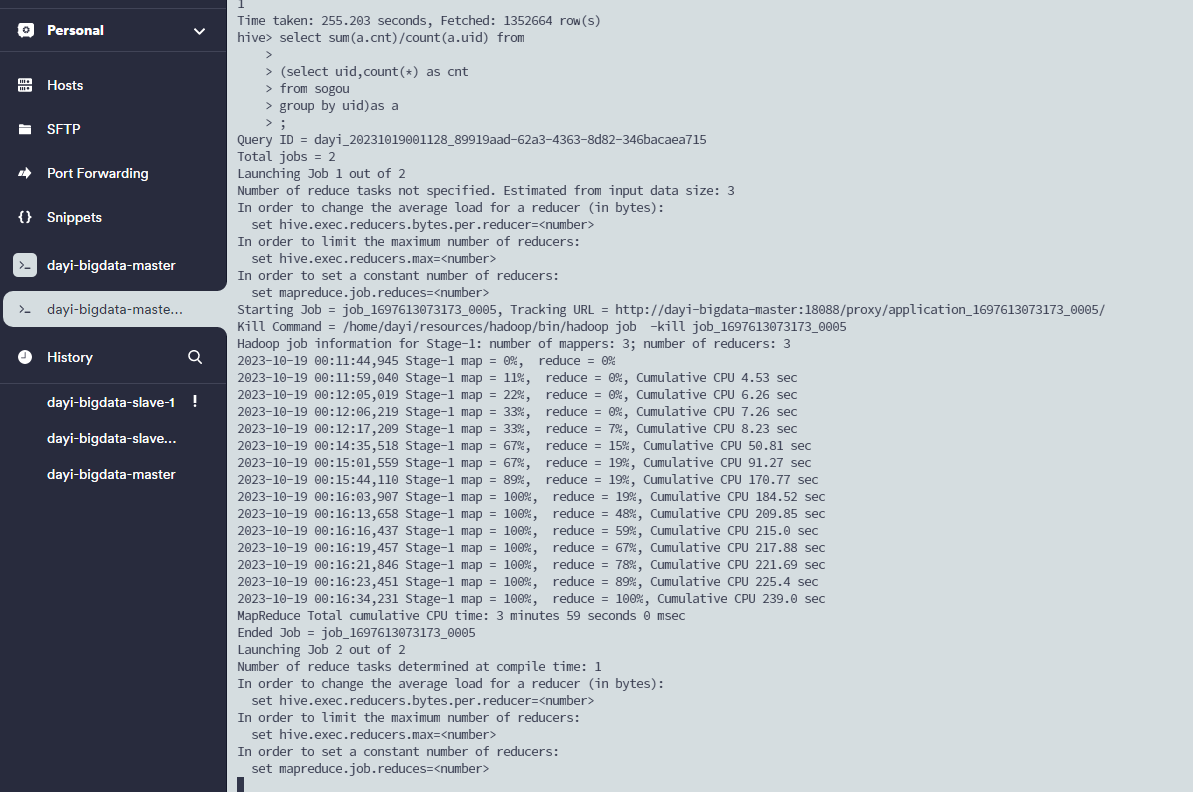
出了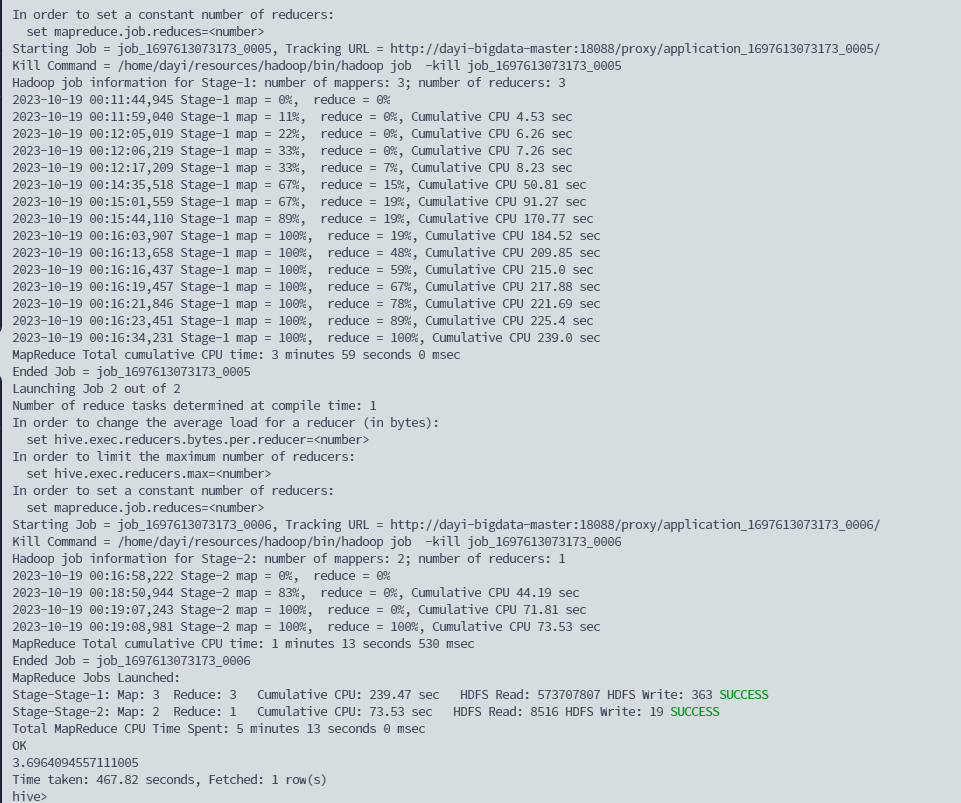
3.6964094557111005
查询频度最高的前10个关键字
SELECT kw, COUNT(kw) AS cnt
FROM sogou
GROUP BY kw
ORDER BY cnt DESC
LIMIT 10;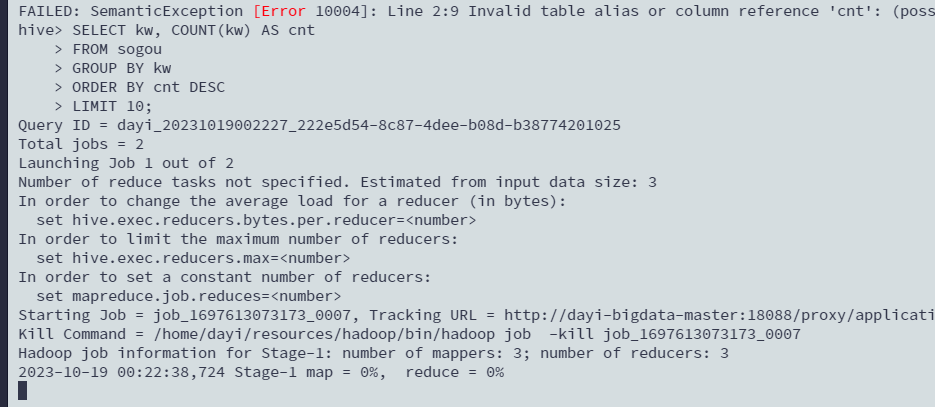
那个URL
好慢hhhh: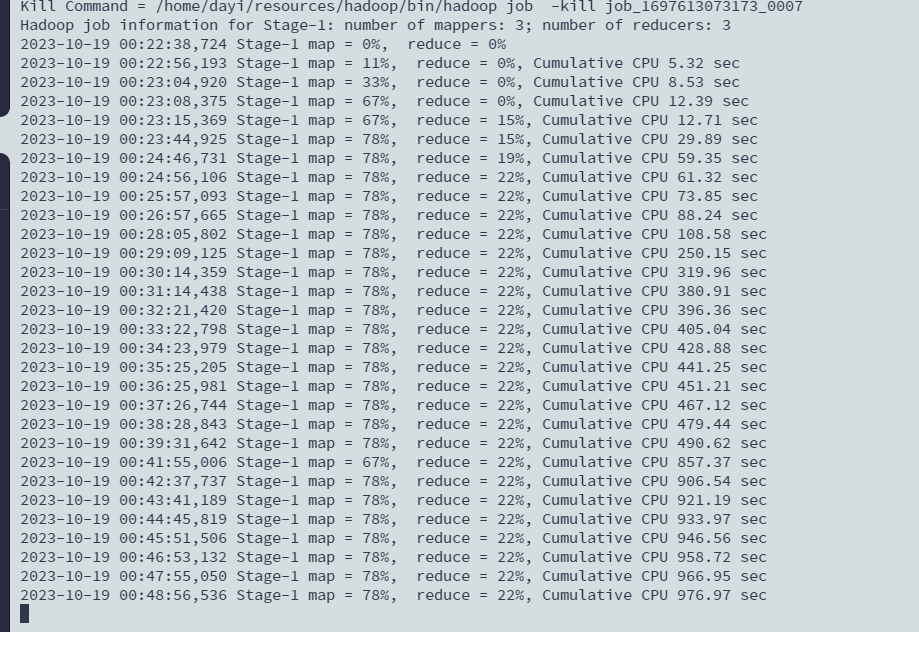
出来了: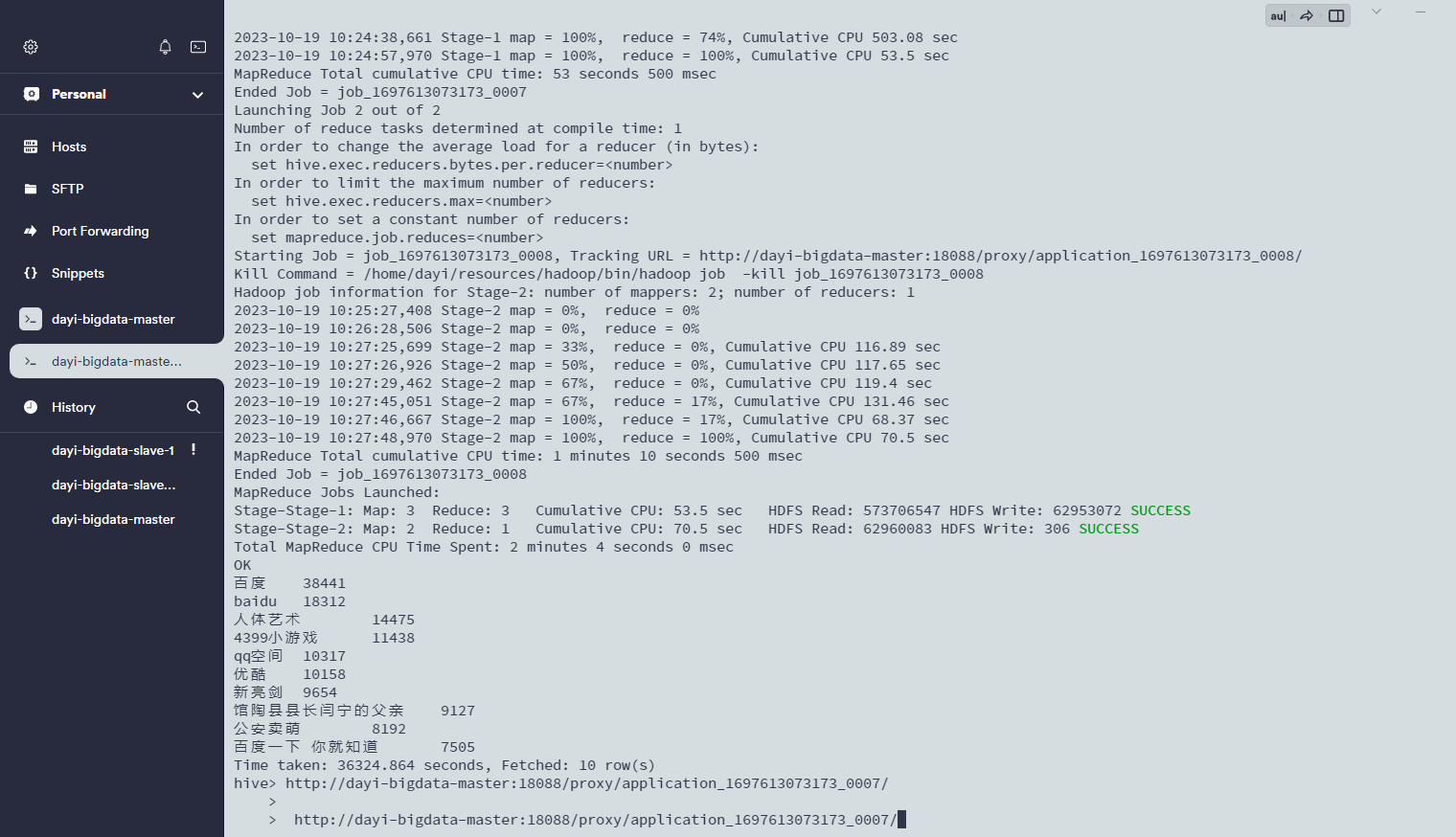
18. zookeeper
1. 复制压缩包
cd resources
tar -zxvf zookeeper-3.4.6.tar.gz
mv zookeeper-3.4.6 zookeeper
recources/zookeeper/conf
文件zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888server.1 服务器编号
master 服务器名
2888 服务端口
3888 选举端口
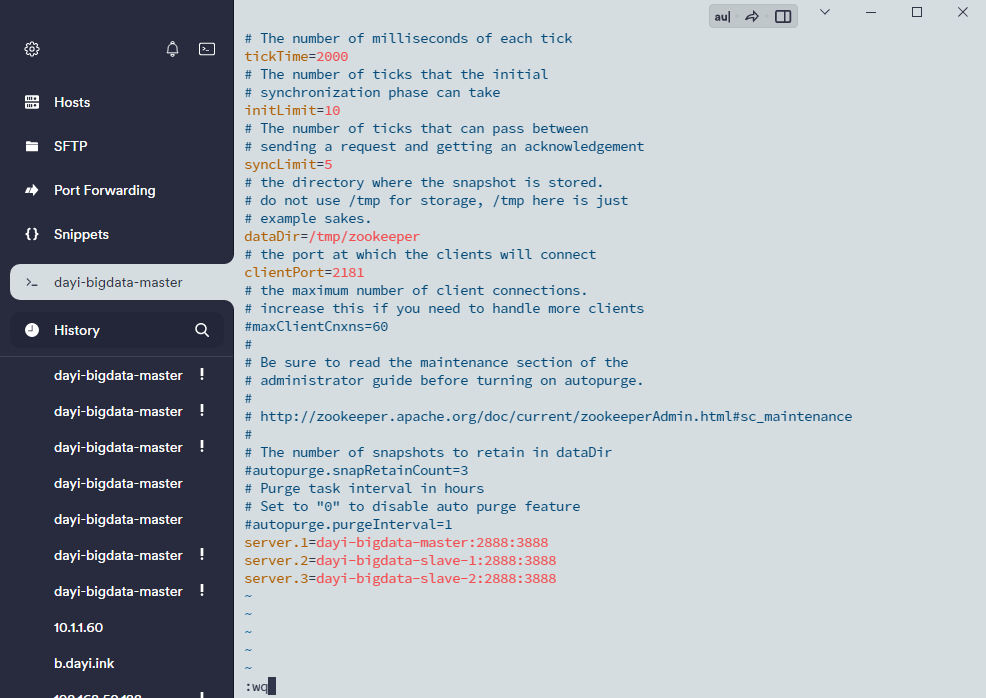
3.创
数据节点表示文件myid
位置 dataDir=/tmp/zookeeper
#位置在内存盘里 重启会丢失
mkdir -pv /tmp/zookeeper
cd /tmp/zookeeper
vi myid
输入1
然后ESC + :wq
# 那样建议这样写
#master
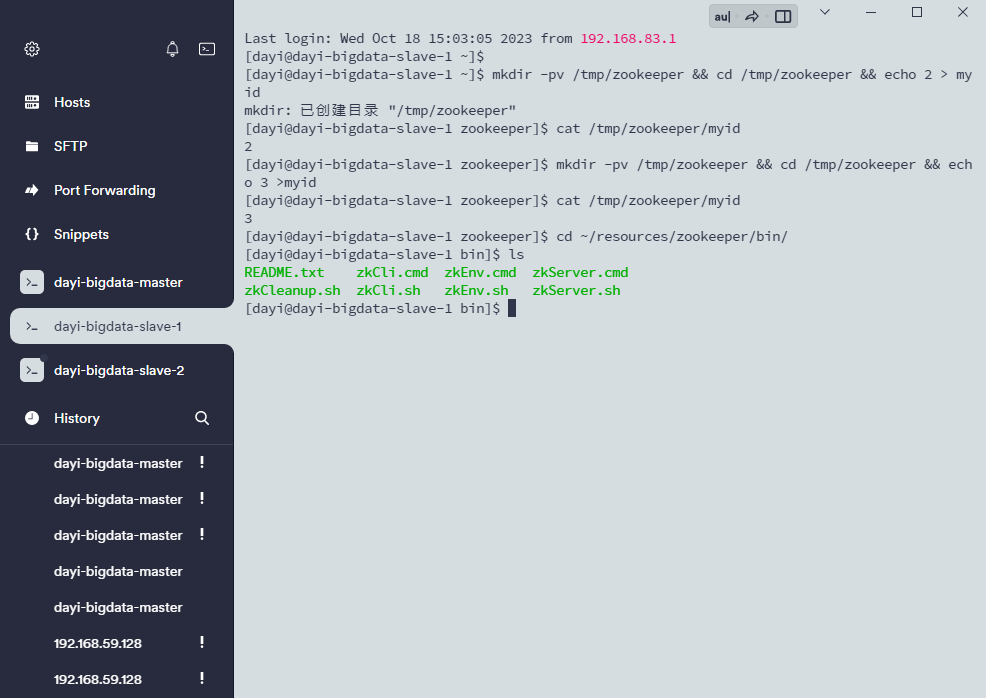
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 1 > myid
cat /tmp/zookeeper/myid
#slave1
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 2 > myid
cat /tmp/zookeeper/myid
#slave2
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 3 >myid
cat /tmp/zookeeper/myid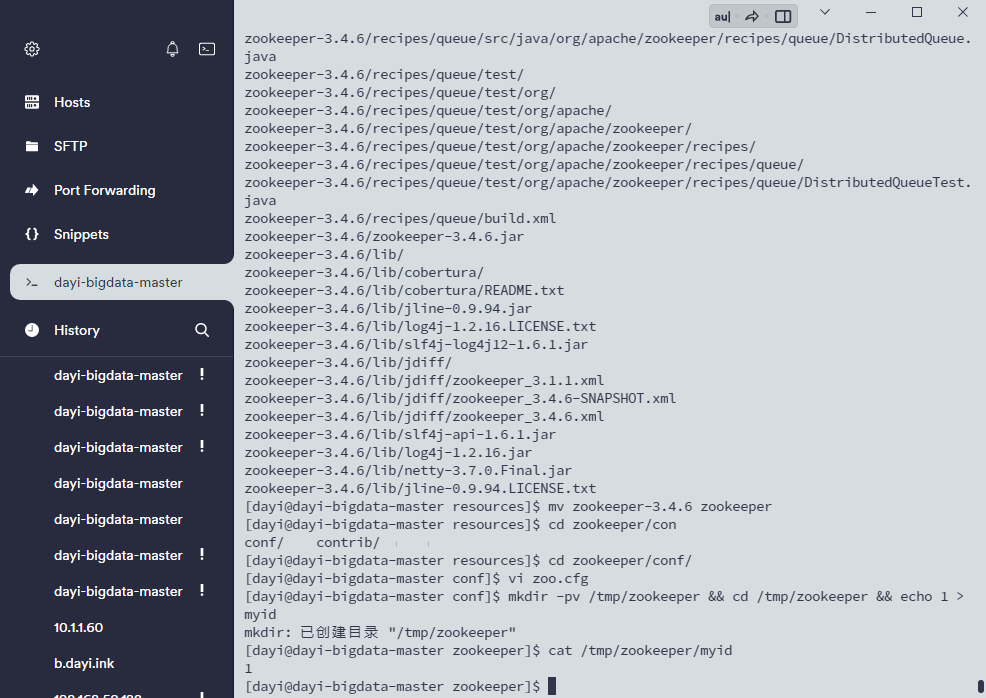
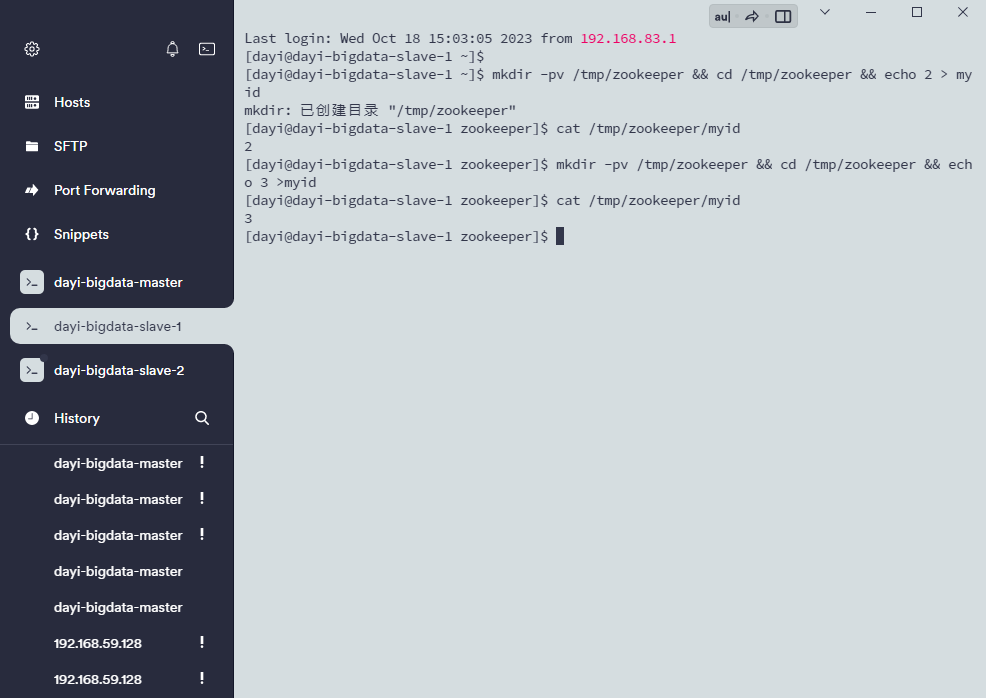
服务器炸了虚拟机没了( )
)
4. 发送zookeeper发送到从节点
cd ~/resources/
ls
scp -r zookeeper slave1:~/resources/
scp -r ~/resources/zookeeper slave2:~/resources/5. 传送bash_profile
scp -r ~/.bash_profile slave1:~/
scp -r ~/.bash_profile slave2:~/
# 从节点分别执行:
source ~/.bash_profile6. 启动zookeeper
cd ~/resources/zookeeper/bin/
ls
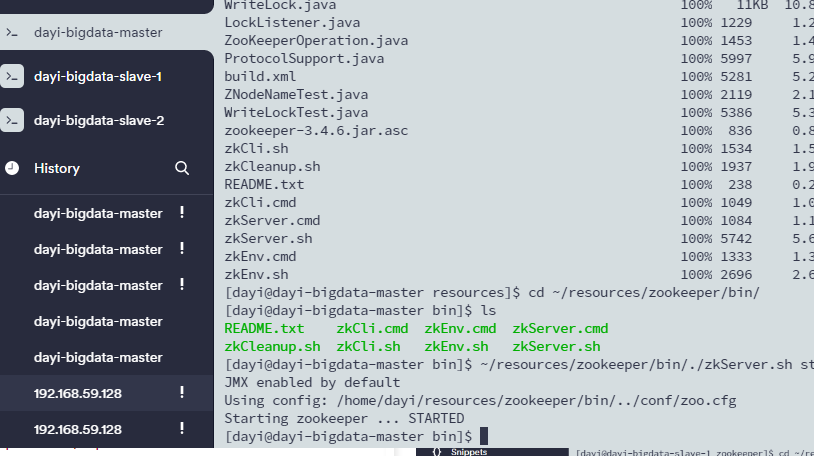
./zkServer.sh start
#一键
~/resources/zookeeper/bin/./zkServer.sh start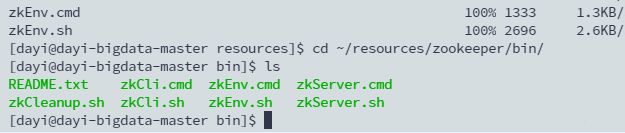
跟上了
验证启动
./zkServer.sh status
这样是正常的
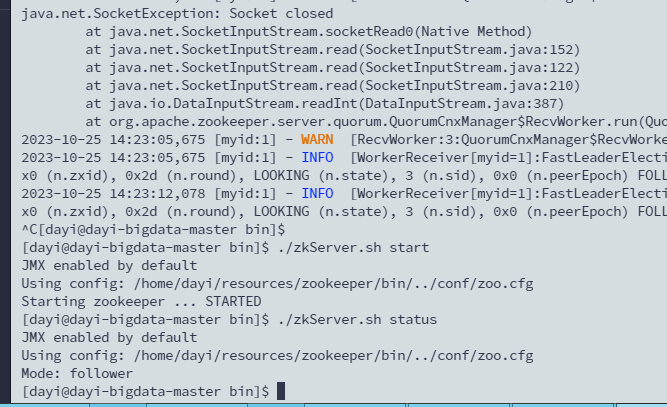
炸了

调试(zkServer.sh print-cmd)
"/home/dayi/resources/jdk/bin/java" -Dzookeeper.log.dir="." -Dzookeeper.root.logger="INFO,CONSOLE" -cp "/home/dayi/resources/zookeeper/bin/../build/classes:/home/dayi/resources/zookeeper/bin/../build/lib/*.jar:/home/dayi/resources/zookeeper/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/dayi/resources/zookeeper/bin/../lib/slf4j-api-1.6.1.jar:/home/dayi/resources/zookeeper/bin/../lib/netty-3.7.0.Final.jar:/home/dayi/resources/zookeeper/bin/../lib/log4j-1.2.16.jar:/home/dayi/resources/zookeeper/bin/../lib/jline-0.9.94.jar:/home/dayi/resources/zookeeper/bin/../zookeeper-3.4.6.jar:/home/dayi/resources/zookeeper/bin/../src/java/lib/*.jar:/home/dayi/resources/zookeeper/bin/../conf:" -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain "/home/dayi/resources/zookeeper/bin/../conf/zoo.cfg"
然后直接复制启动(你的跟我的不一样)
在这里看看报错是什么
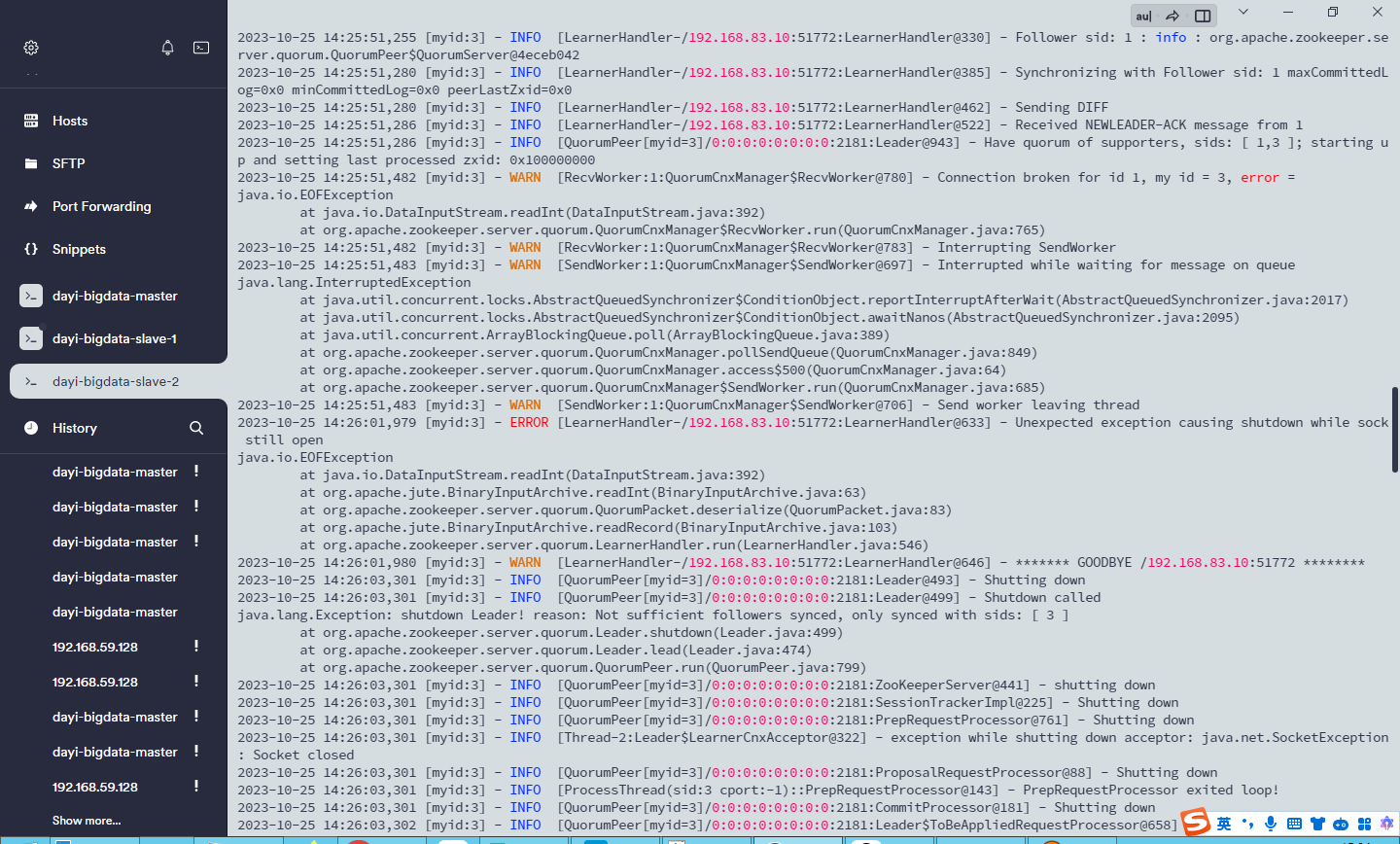
出现错误看看这个文件是否正常
/tmp/zookeeper/myid
19. 安装hbase
1. 复制文件解压缩
cd ~/resources/
tar -zxvf hbase-0.98.9-hadoop2-bin.tar.gz
mv hbase-0.98.9-hadoop2 hbase
2. 修改配置文件
文件1
~/resources/hbase/conf/hbase-env.sh
29 行:
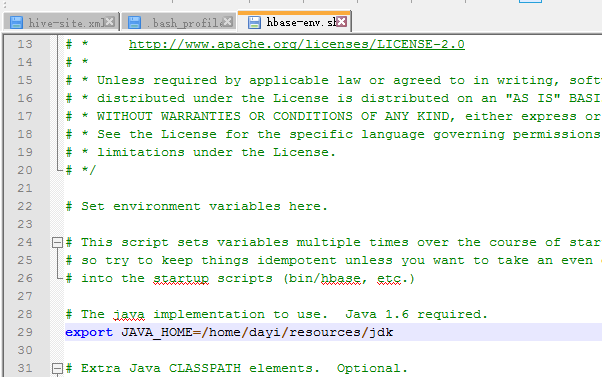
获得JAVA_HOME:
echo $JAVA_HOME
124行:
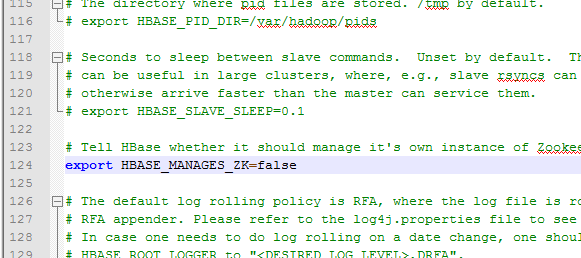
true : 使用habase自带的ZK(你启动失败了zookeeper)
false : 不使用hbase自带的ZK (上节课启动成功)
文件2
~/resources/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>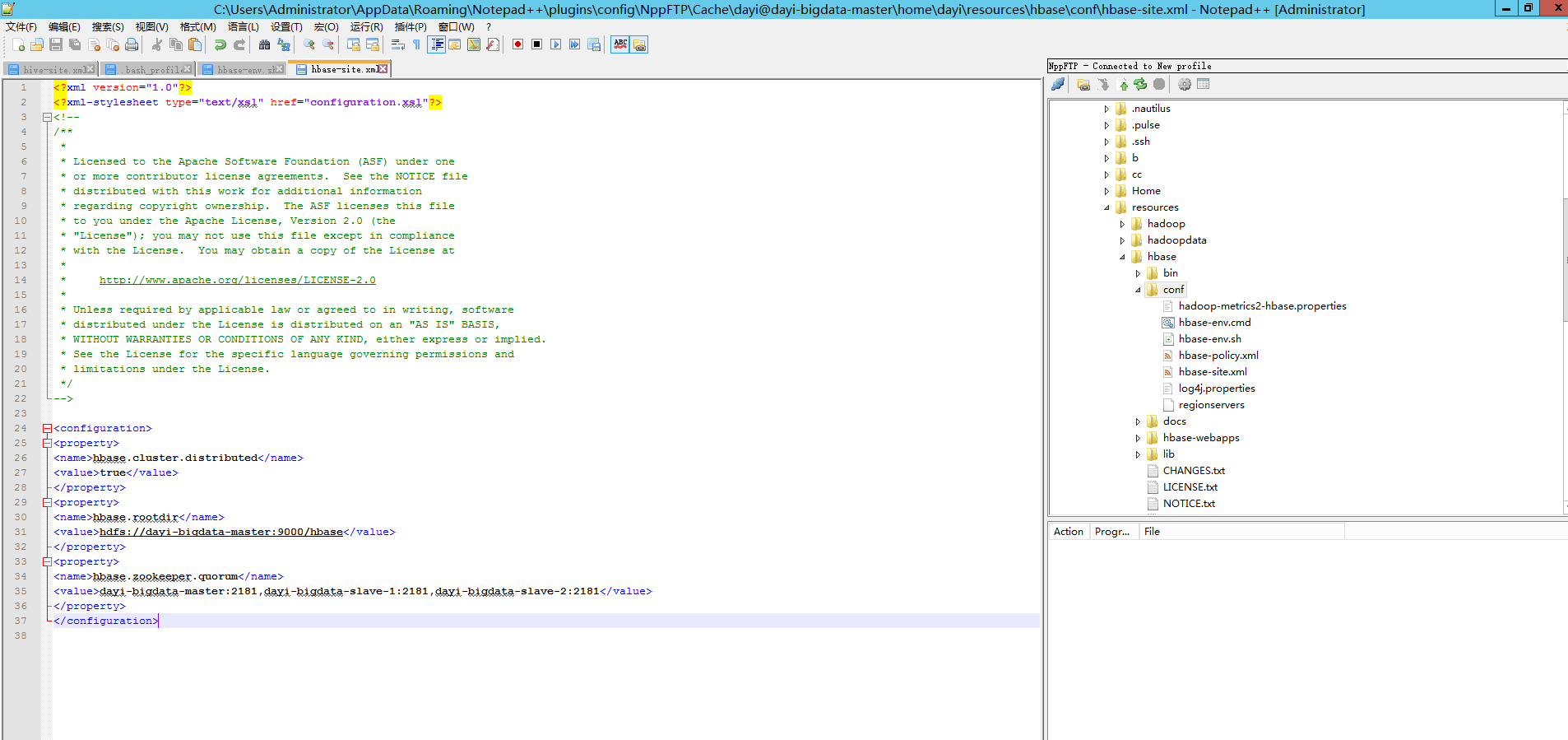
文件3
regionservers
3. 添加环境变量
export HBASE_HOME=~/resources/hbase
export PATH=$PATH:$HBASE_HOME/bin
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*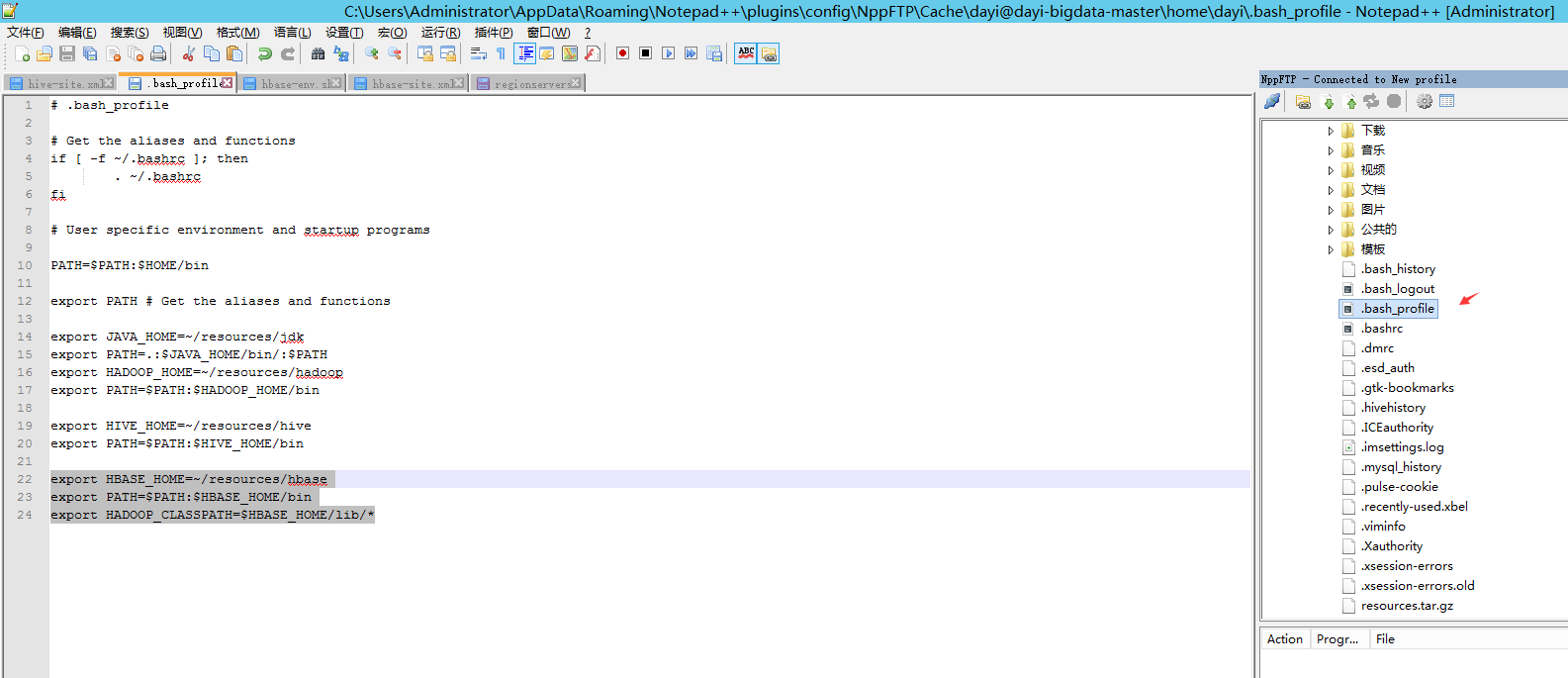
保存后,sources一下
两个从节点:
source ~/.bash_profile4. 传送文件
scp -r ~/resources/hbase slave1:~/resources/
scp -r ~/resources/hbase slave2:~/resources/
scp -r ~/.bash_profile slave1:~/
scp -r ~/.bash_profile slave2:~/
source一下
#slave1
source ~/.bash_profile
#slave2
source ~/.bash_profile5. 原神启动
hadoop
~/resources/hadoop/sbin/./start-all.sh这种情况重新执行一下就行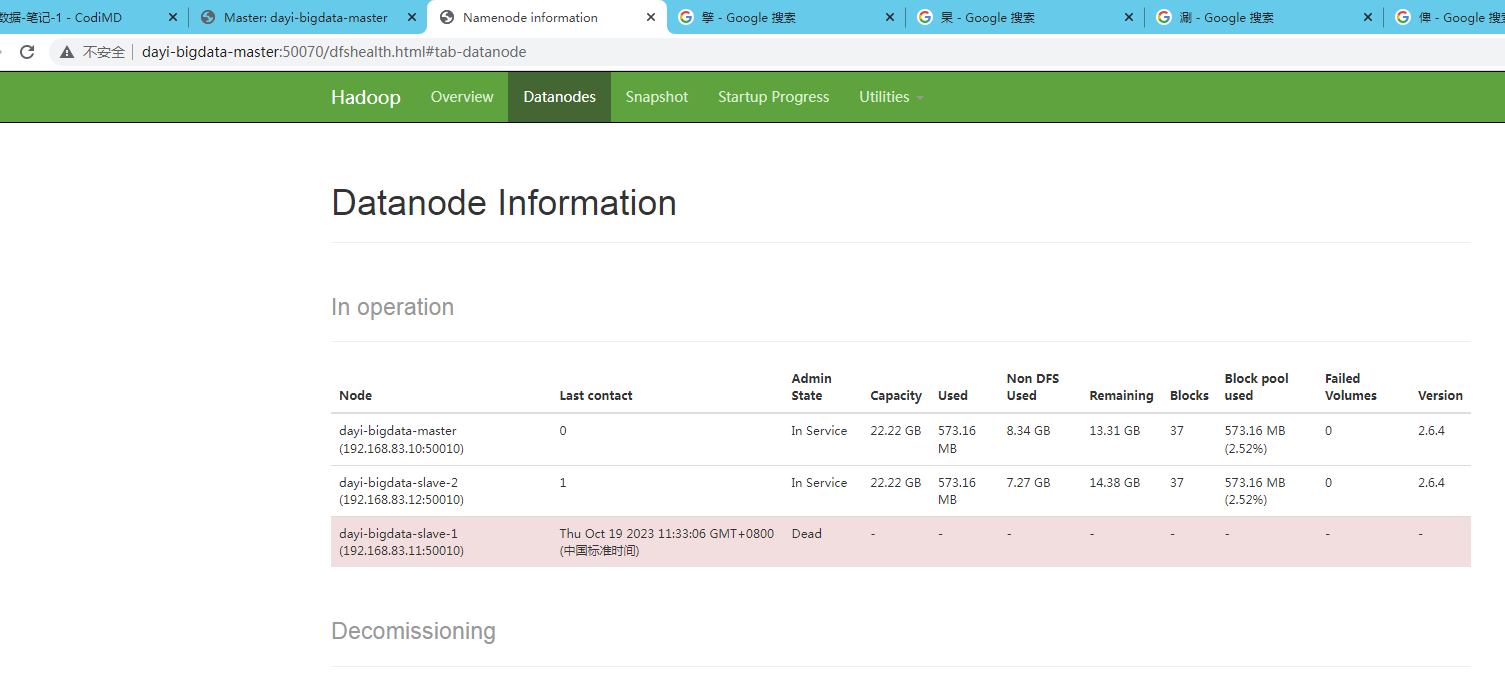
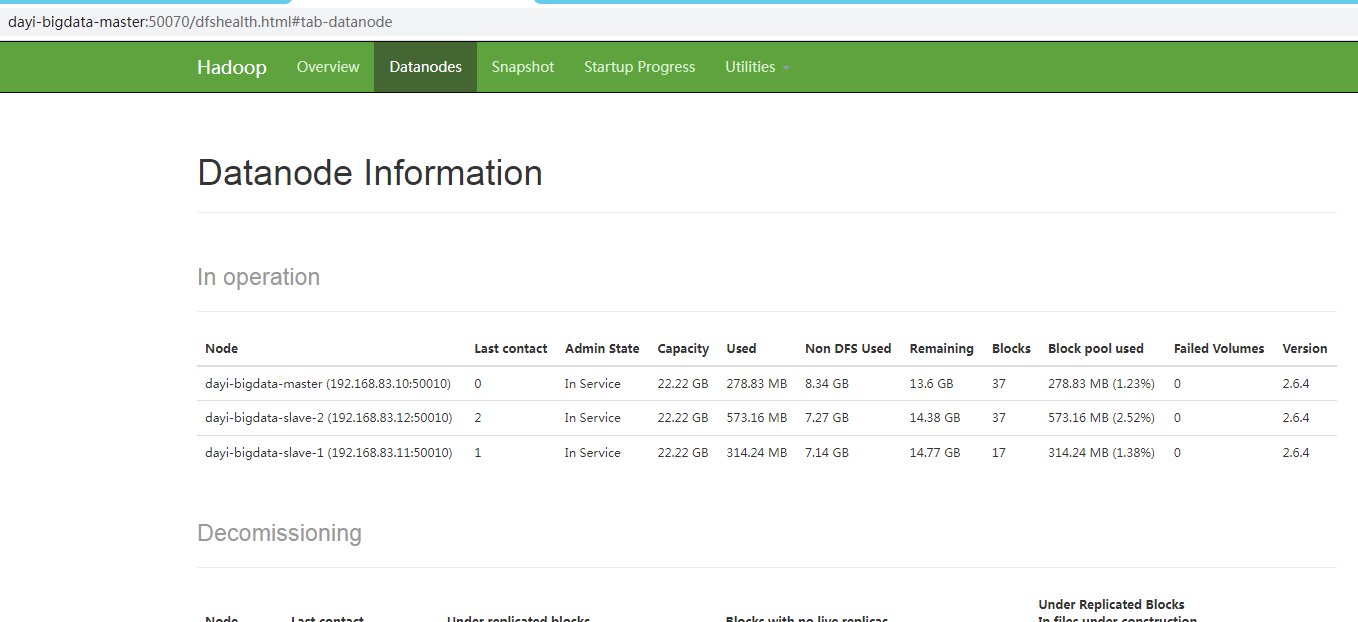
zookeeper
#master
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 1 > myid
~/resources/zookeeper/bin/./zkServer.sh start
#slave1
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 2 > myid
~/resources/zookeeper/bin/./zkServer.sh start
#slave2
mkdir -pv /tmp/zookeeper && cd /tmp/zookeeper && echo 3 >myid
~/resources/zookeeper/bin/./zkServer.sh start验证:
~/resources/zookeeper/bin/./zkServer.sh status
lader or following
hbase
~/resources/hbase/bin/start-hbase.sh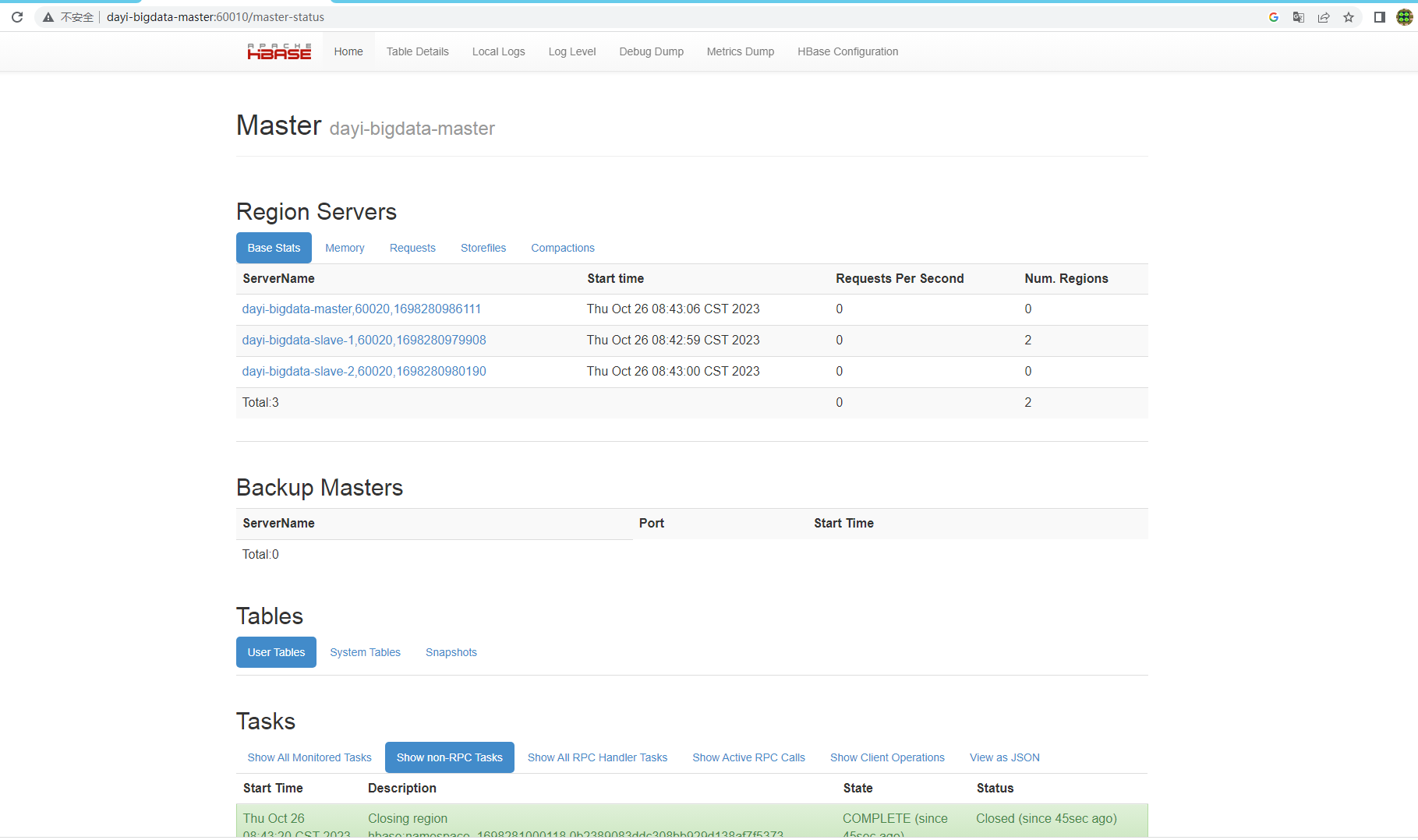
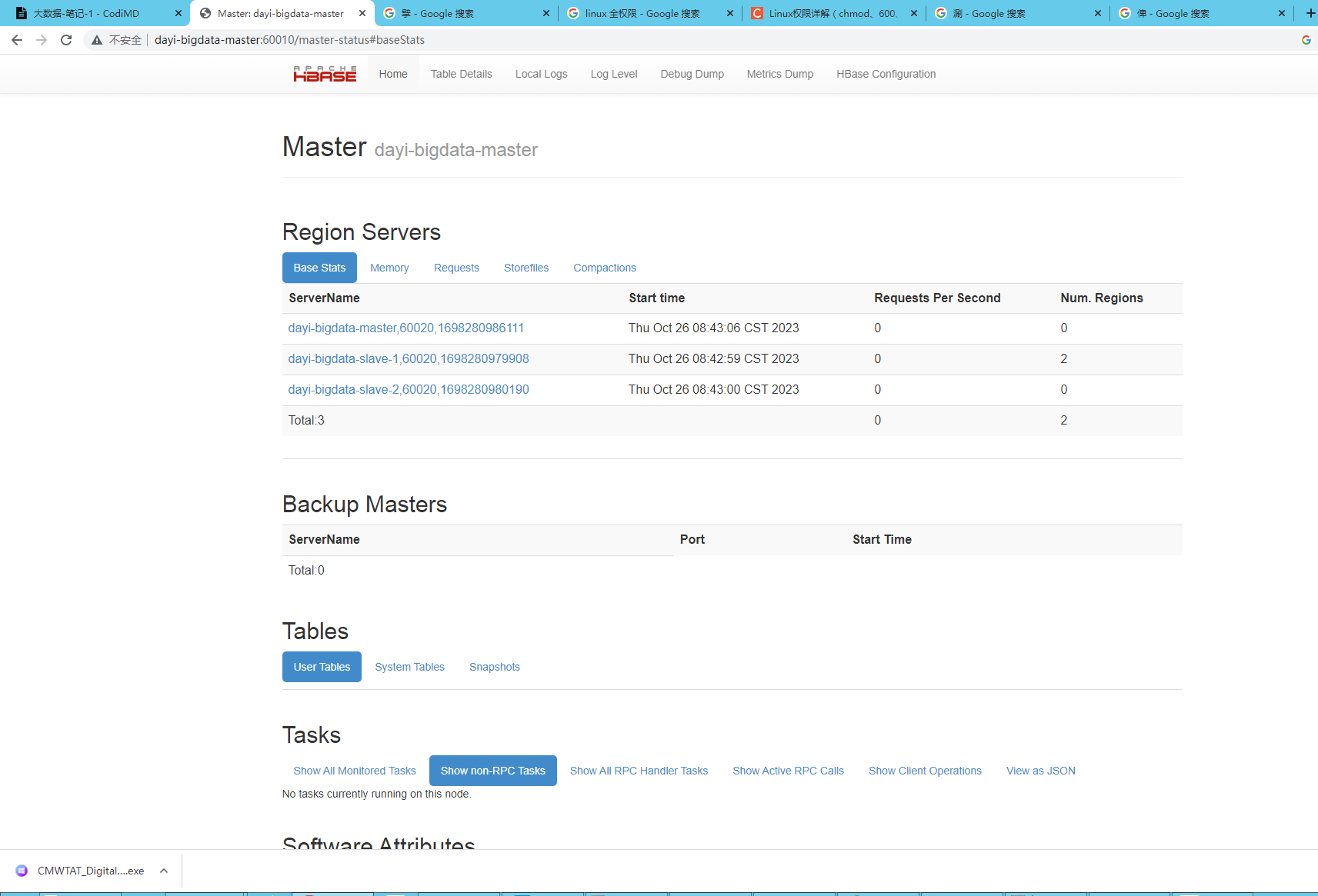
20. hbase使用
1. shell
hbase shell

2. CRT
3. 命令1 list

4. 命令2 新建表
create 'stu','info','score'
表名 列族1 列族2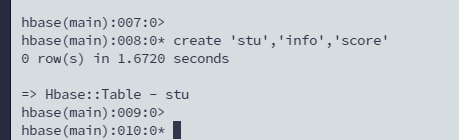
4. 命令3 写数据
尽量不要超过三列
put 'stu','1','info:name','John'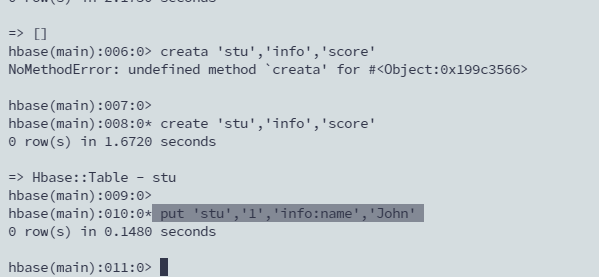
put 'stu','2','info:age',20
put 'stu','3','info:name','Mary'
put 'stu','3','info:age',19
put 'stu','3','score:math',90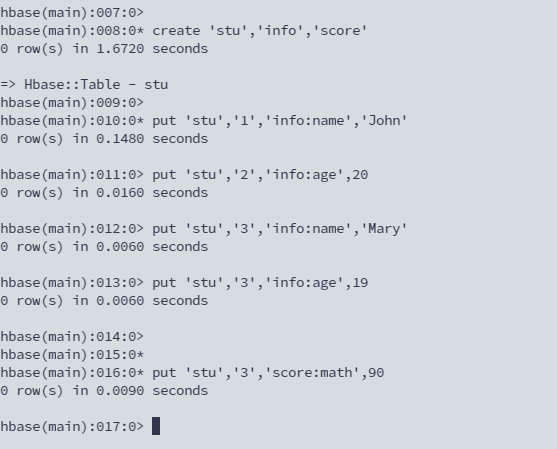
5. 读数据
两种方式
get 'stu','1'
get 'stu','3'
scan 读所有行
scan 'stu'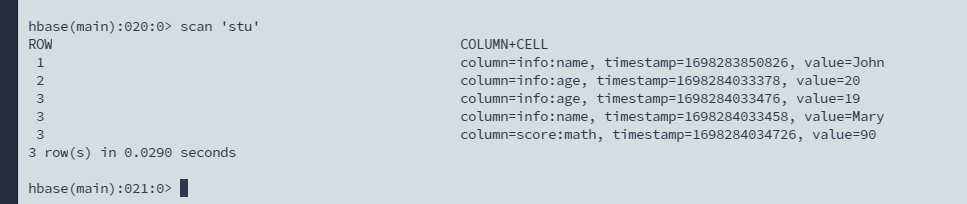
查看表结构
describe 'stu'
Table stu is ENABLED
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'score', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
2 row(s) in 0.0680 seconds6. 删除
删单元格
delete 'stu','3','score:Math'
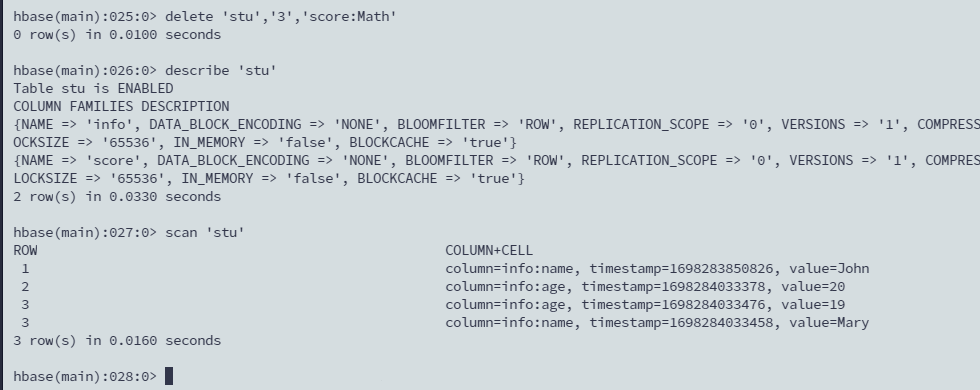
删除失败好像不会报错。
删行
deleteall 'stu','2'
scan 'stu'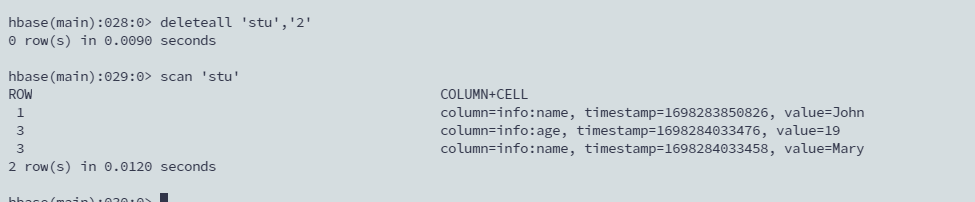
删表
- 先让表失效
- 删除表
disable 'stu'
drop 'stu'
list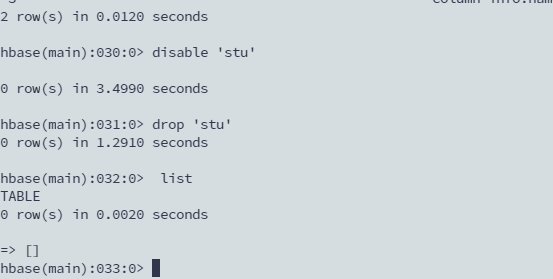
20 MapReduce
肚子疼死了
拉肚子拉的有点自闭,上课没跟上
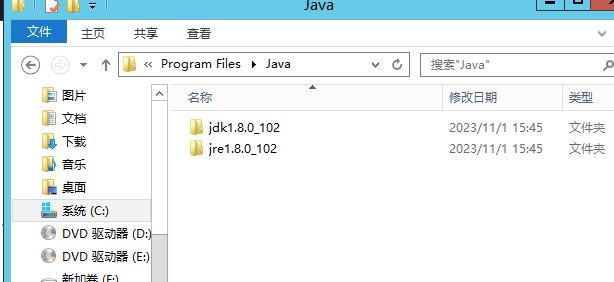
1. 安装JDK
jdk-8u102-windows-x64.exe
安装目录不要带有中文,可以的话推荐选择C:\Program Files\Java或者D:\Program Files\Java
有闸瓦环境了非1.8版本也建议再装一个。
2. 解压缩hadoop
- 想法子把这个文件
hadoop-2.6.4.tar.gz解压了
- 推荐放到目录:
D:\hadoop\hadoop-2.6.4
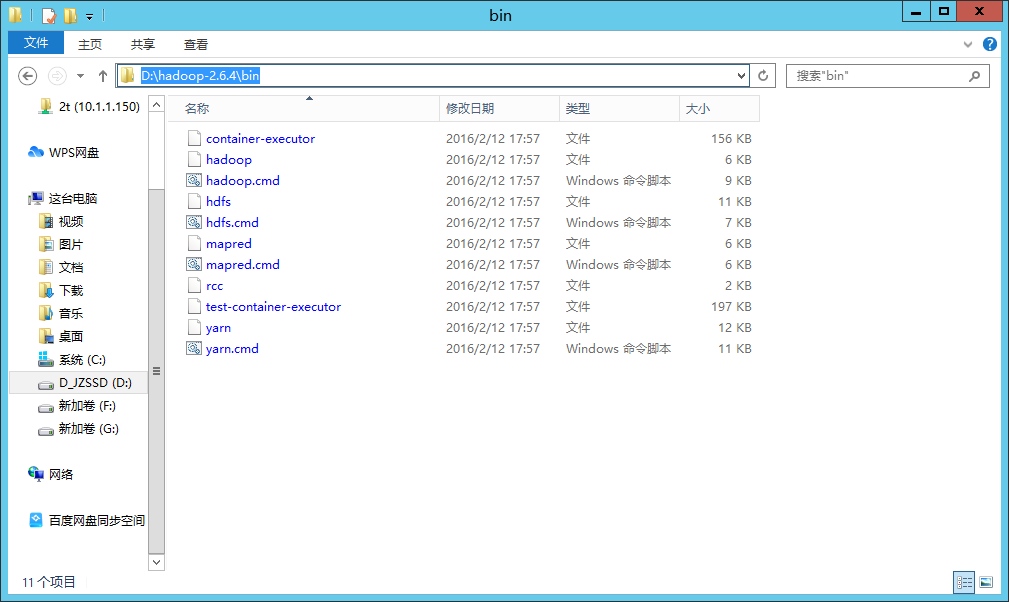
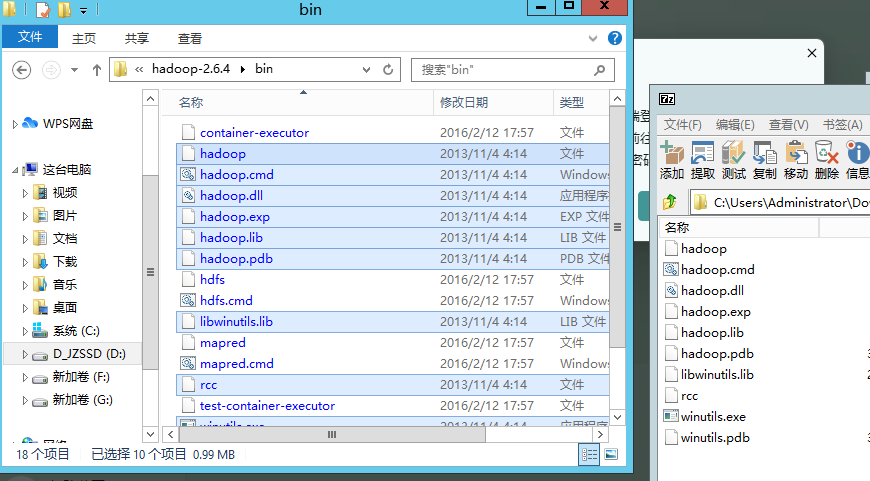
- 然后修补下hadoop
需要替换文件直接替换即可。
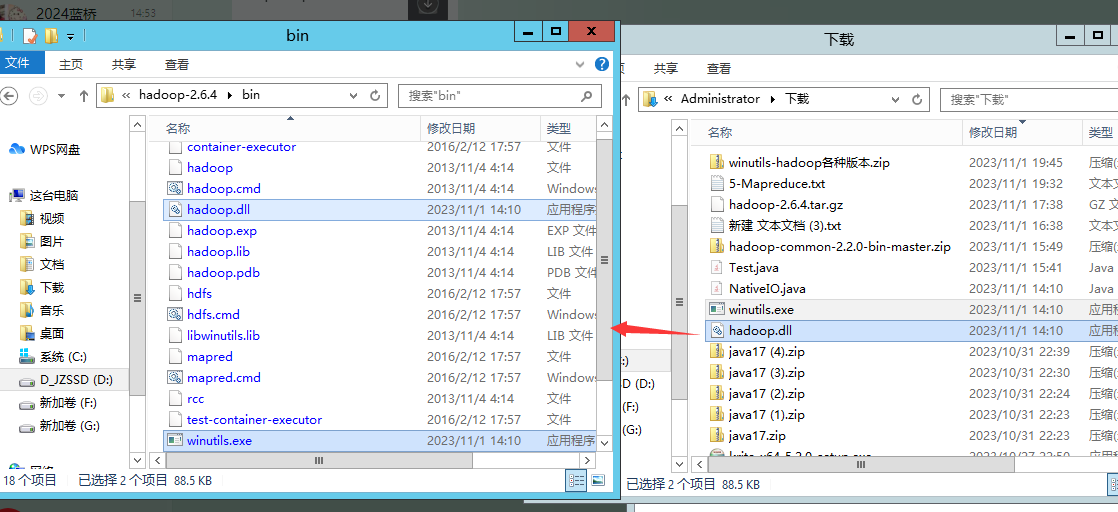
D:\hadoop\hadoop-2.6.4\bin里面放下:
hadoop-common-2.2.0-bin-master.zip里面的bin目录(替换文件)。hadoop.dll放入D:\hadoop\hadoop-2.6.4\bin(替换)winutils.exe放入D:\hadoop\hadoop-2.6.4\bin(替换)
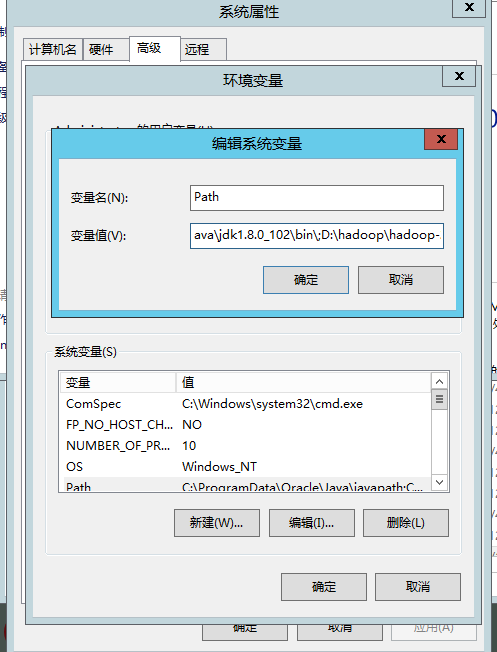
3. 配置环境变量
这一步就是加4个(3个)环境变量,没那么复杂,但是会根据你电脑的实际情况有所不一样。所以篇幅比较大
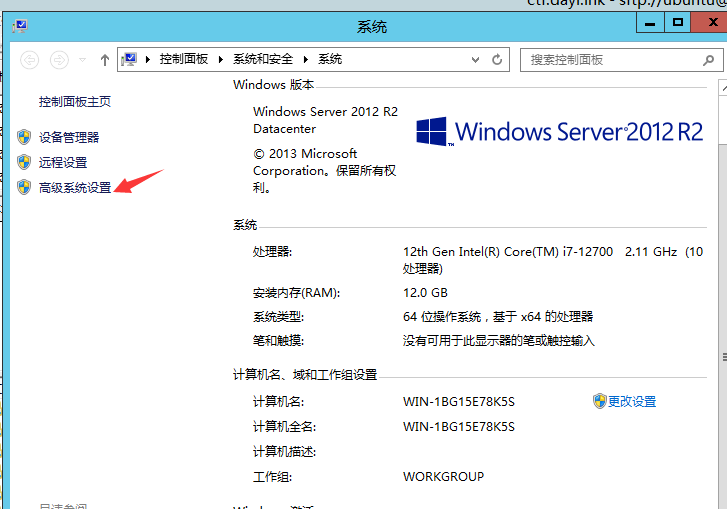
如何修改环境变量?
此电脑/这台电脑/计算机(在文件管理器里,防止你桌面的是个快捷方式)->右键 属性-> 找到高级系统设置—>高级->环境变量按你实际修改目录,用户变量和系统变量都可以。

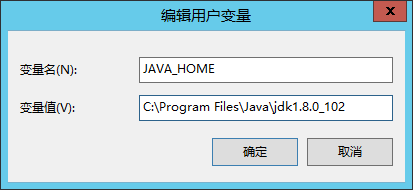
好像如果JAVA_HOME目录有空格的话会有些问题,
JAVA_HOME:C:\Program Files\Java\jdk1.8.0_102
classpath:.;C:\Program Files\Java\jdk1.8.0_102\lib\dt.jar;C:\Program Files\Java\jdk1.8.0_102\lib\tools.jar;C:\Program Files\Java\jdk1.8.0_102\binHADOOP_HOME:D:\hadoop\hadoop-2.6.4Path(不要跟*天宇一样直接删了再加,在原来的基础上修改,你的系统不应该没有这个环境变量参数(Path),请先找找,这个环境变量是有顺序的,前面的会优先遍历) :- 这种的添加
;C:\Program Files\Java\jdk1.8.0_102\bin\;D:\hadoop\hadoop-2.6.4\bin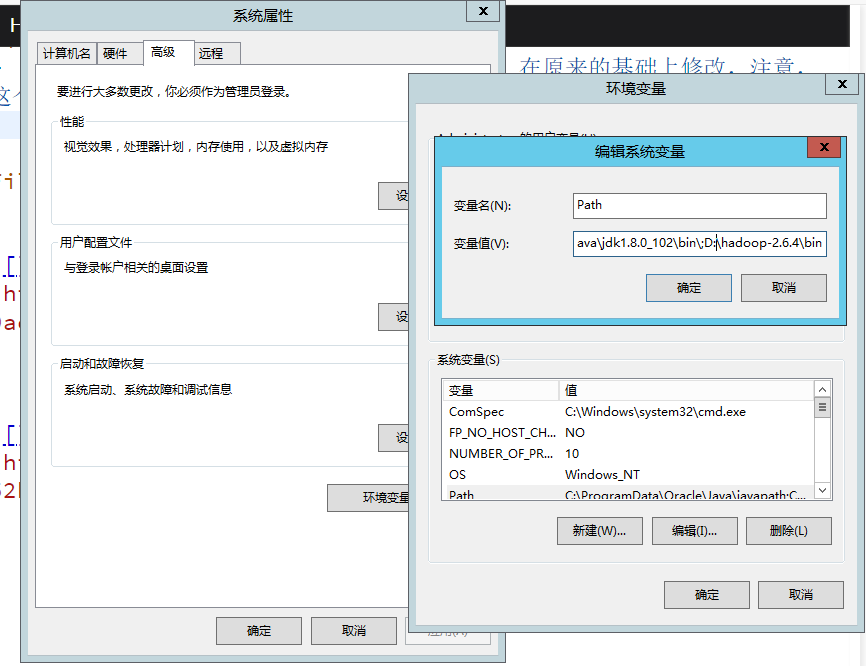
这种的新建两个条目,移动到最上面去
C:\Program Files\Java\jdk1.8.0_102\bin\D:\hadoop\hadoop-2.6.4\bin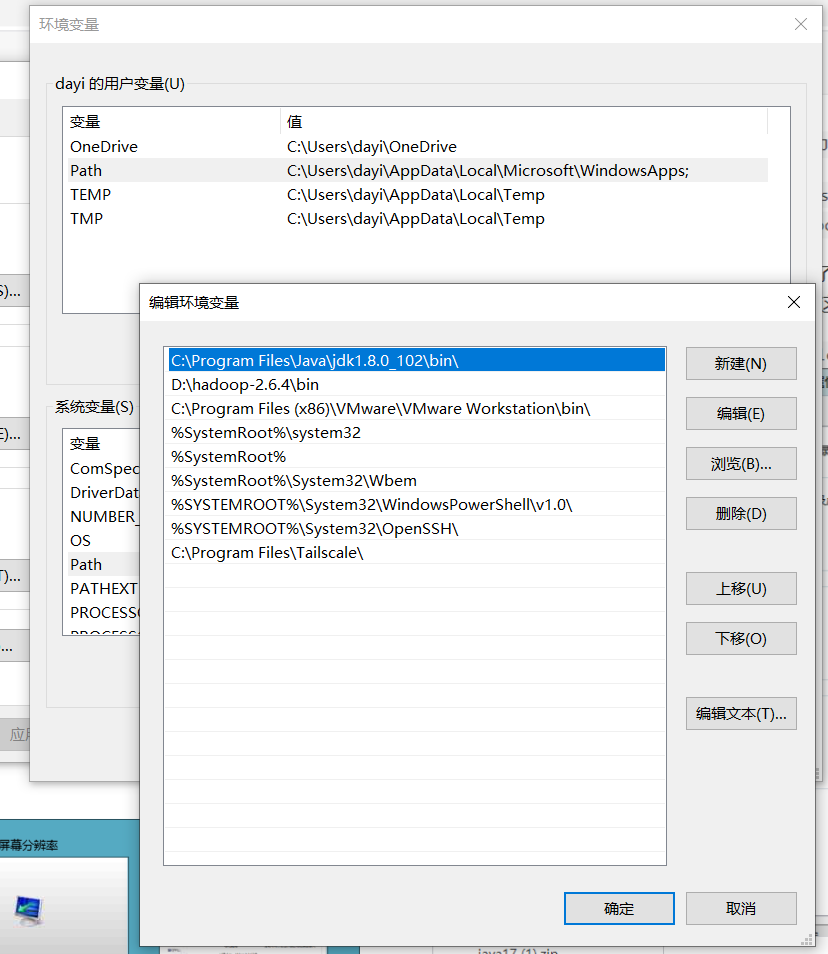
- 这种的添加
- 验证环境变量
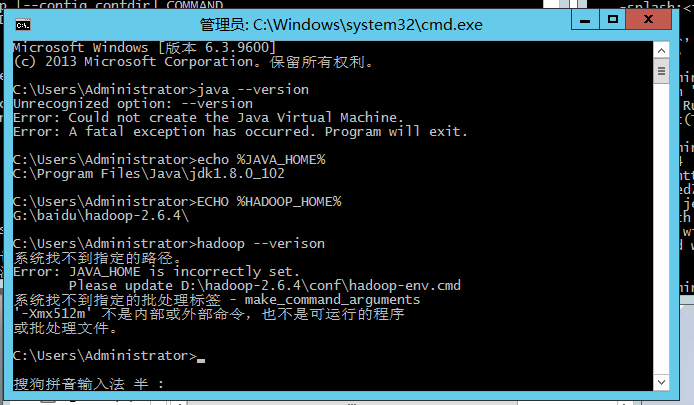
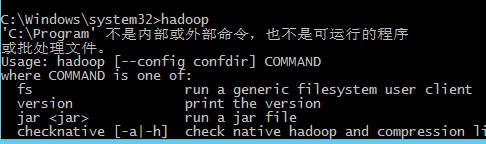
java -version
echo %JAVA_HOME%
ECHO %HADOOP_HOME%
hadoop verisonD:\jdk\jdk1.8.0_102
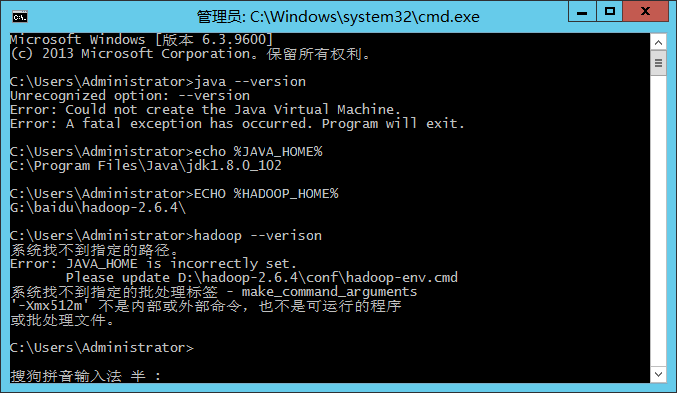
遇到这个问题: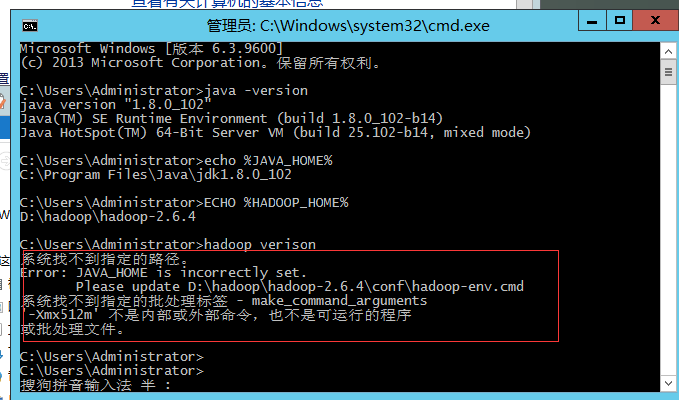
我也不知道影不影响,原因是:Program Files中存在空格,然后他不能正常用,两个方法:
- 方法1:把
JAVA_HOME环境变量中的Program Files改为:PROGRA~1,比如这里我改为了:C:\PROGRA~1\Java\jdk1.8.0_102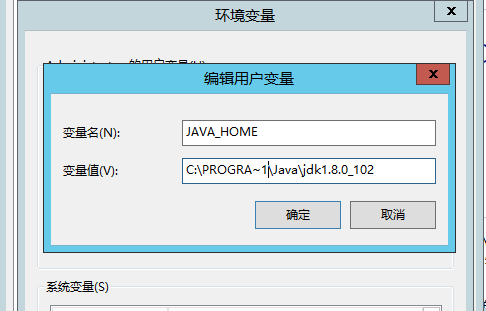
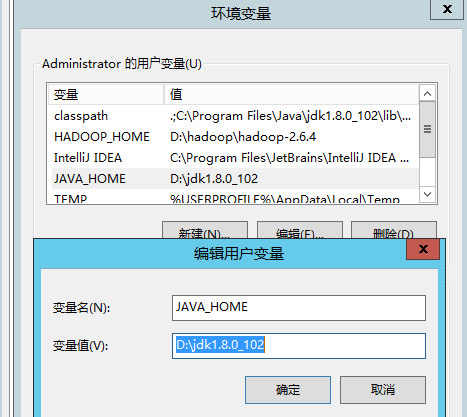
- 方法2(推荐):把JDK复制一份到普通目录中(不带空格),然后修改
JAVA_HOME到这里
- 方法三:虽然我带着的空格,但是跑起来很正常,老师跟我说是这样(求告知)
他这个JAVA_HOME的路径带空格好像会奇奇怪怪的
改成JAVA_HOME = "C:/xxxxx/jre1.8_102"(带引号会这样)
复制了jdk到没空格的目录
把hadoop的env
这样好像可以
感觉不应该呀,带空格就识别不出来感觉不至于有这种低级问题bia
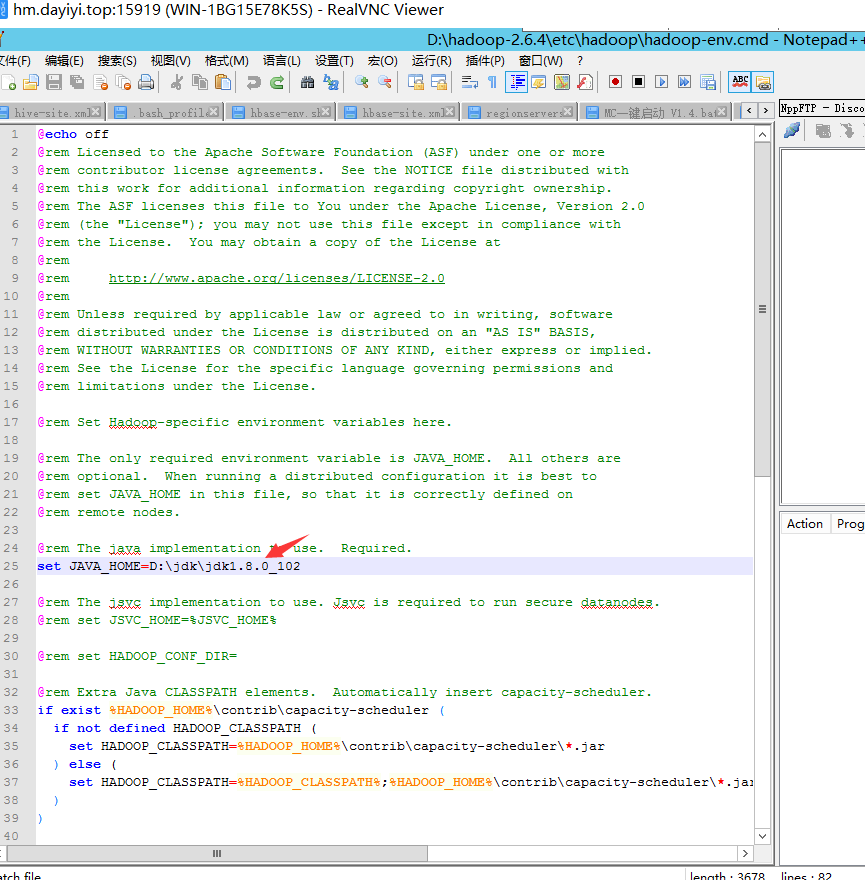
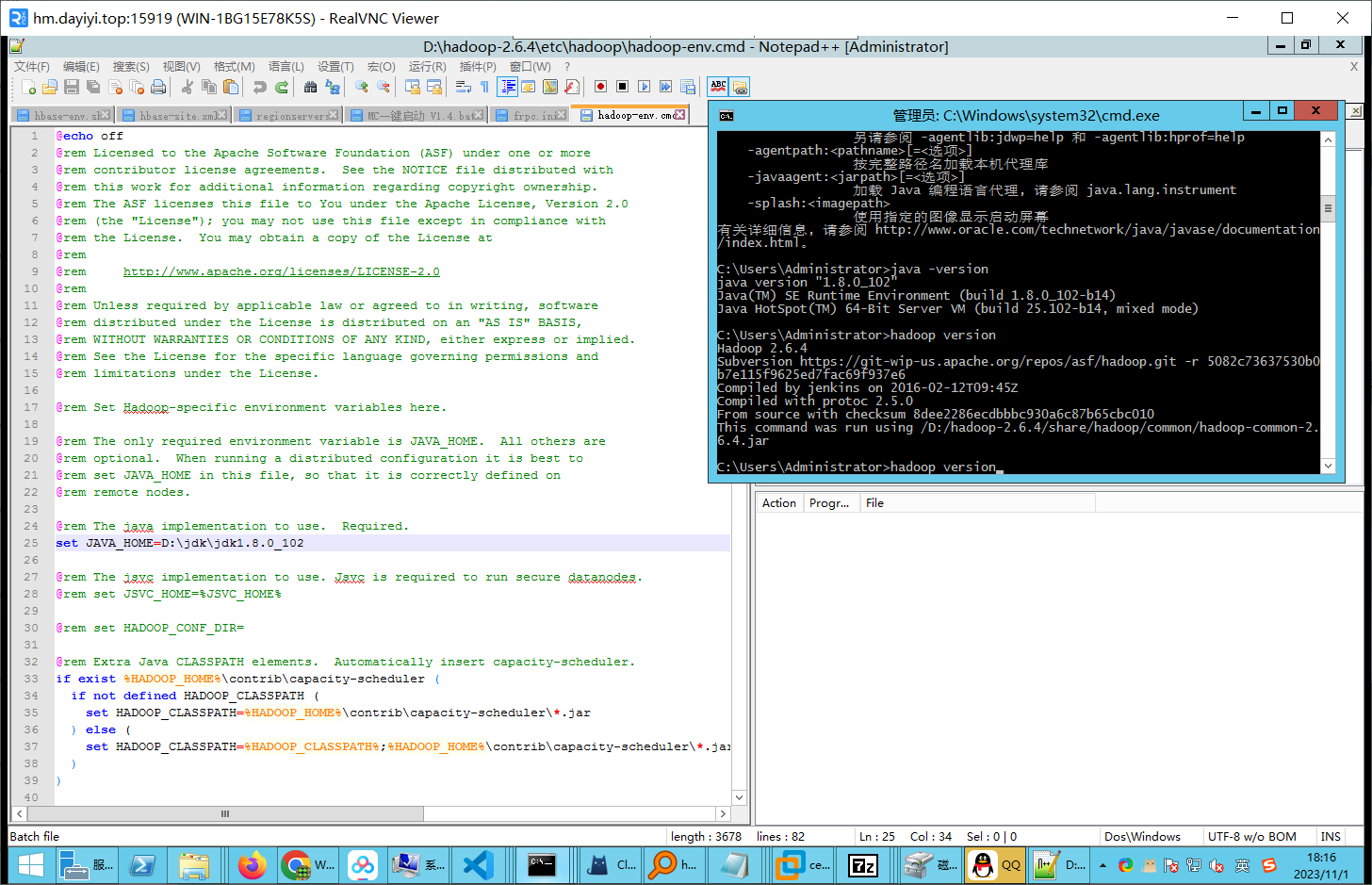

- 也可以尝试修改这个文件的25行
D:\hadoop\hadoop-2.6.4\etc\hadoop\hadoop-env.cmd
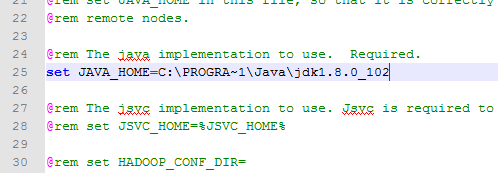
总之:
执行:
java -version
echo %JAVA_HOME%
ECHO %HADOOP_HOME%
hadoop verison第一行和最后一行的结果应该这样,但是你的如果有点多余的东西,应该也不是很影响?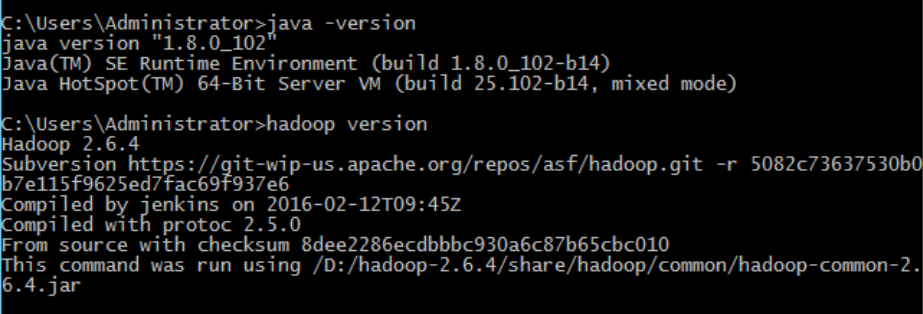
4. 新建项目
1. 配置Eclipse
感谢王策哥哥
windows->preference->java->install JREs->add->standard VM
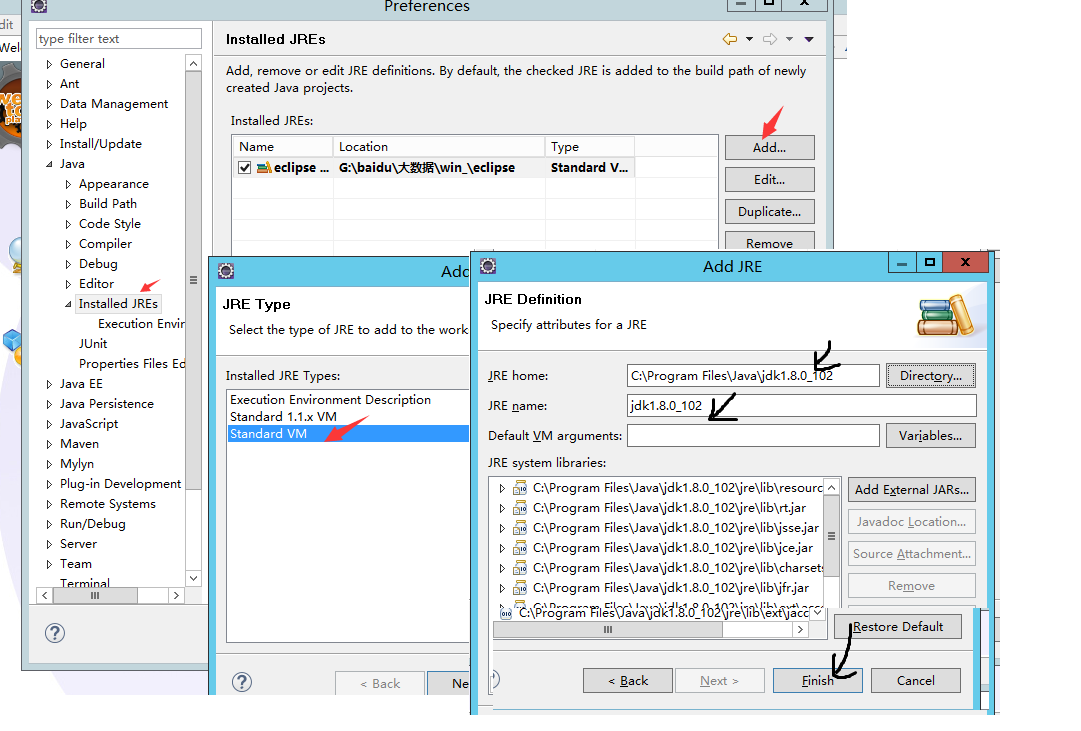
2. 新建工程
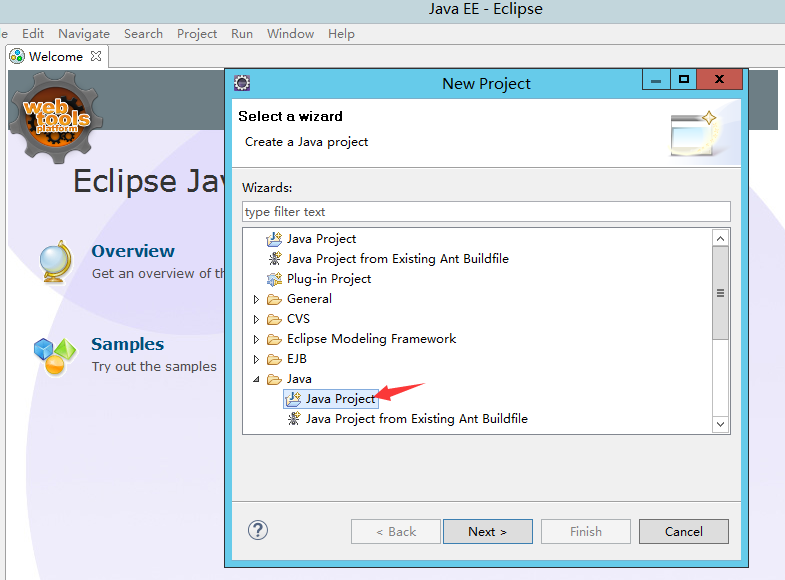
感谢王策file->new project->java project->next->name->finish
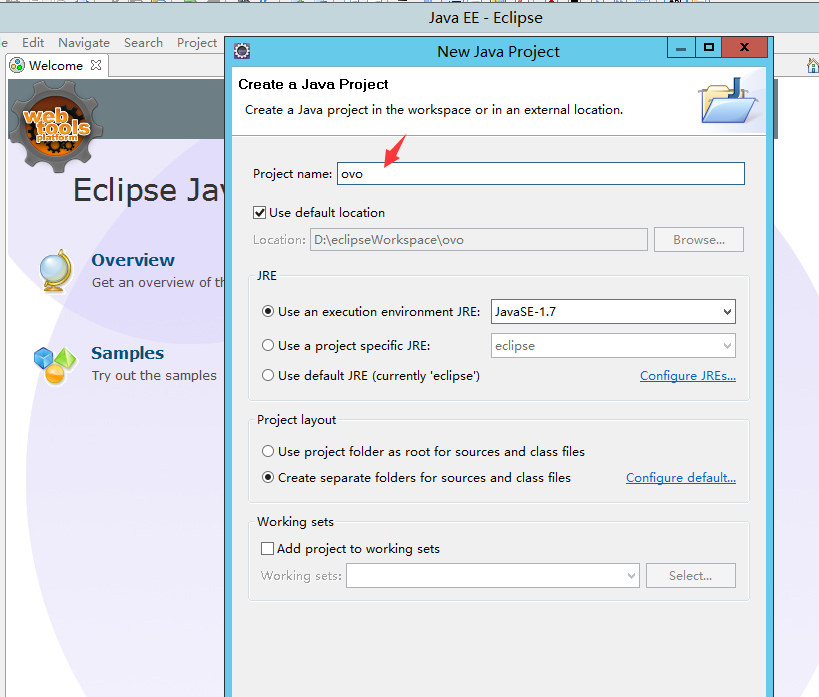
3. 导包
- ALT+ENTER 打开项目设置
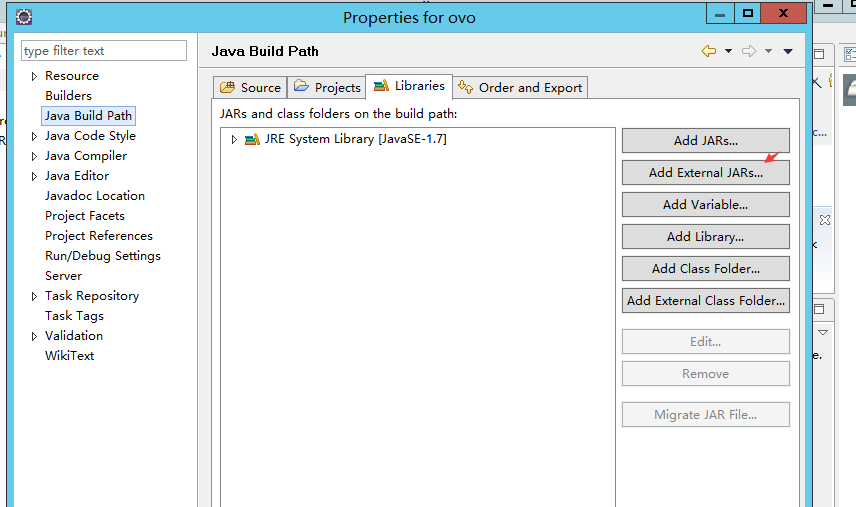
JAVA BUILD PATH-> 添加外部库- 导入hadoop环境jar包
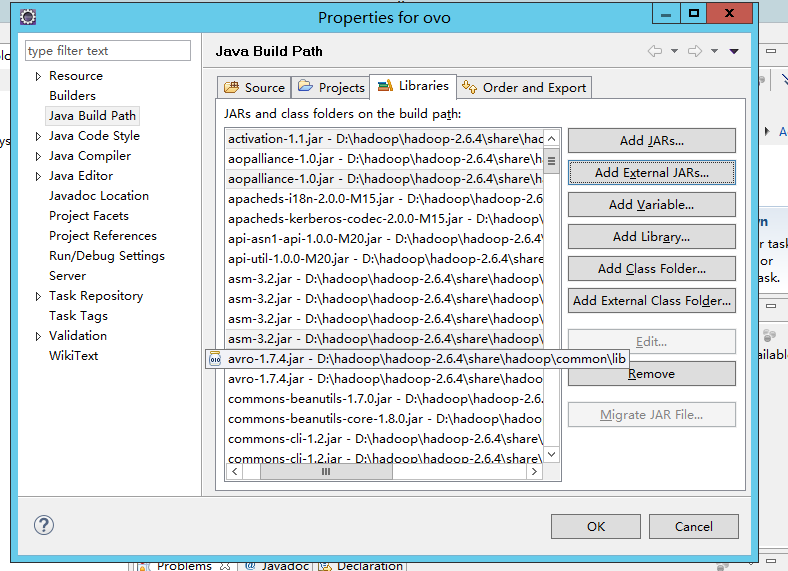
D:\hadoop\hadoop-2.6.4\share\hadoop\common所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\common\lib所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\hdfs所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\hdfs\lib所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\mapreduce所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\mapreduce\lib所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\yarn所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\yarn\lib所有jar包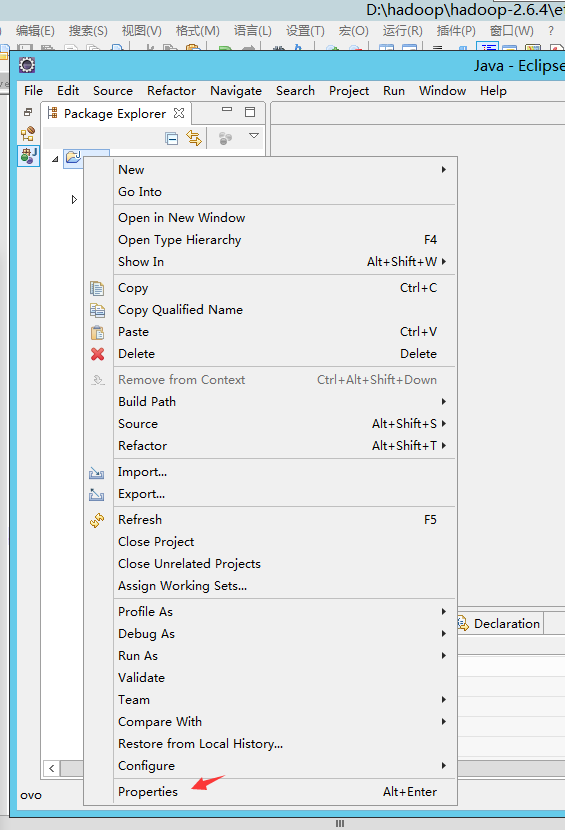
5. 新建包
新建org.apache.hadoop.io.nativeio
org.apache.hadoop.io.nativeio
然后把NativeIO.java弄到包里
可以直接拖过来
新建包 my
my
同样的,把文件弄过去
如果需要修改的话这里:
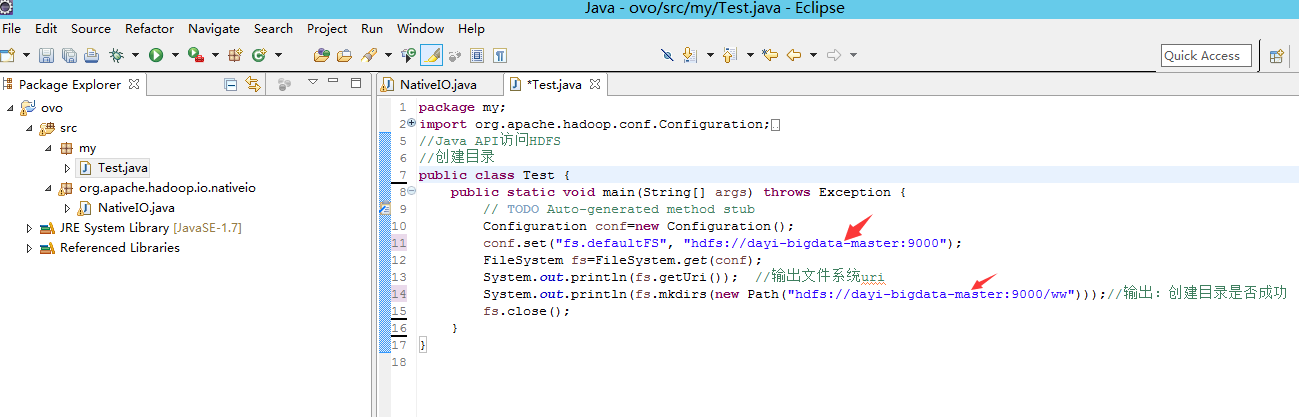
到master下修改下目录权限
master
#启动hadoop
~/resources/hadoop/sbin/./start-all.sh看看网页:
http://master:50070/dfshealth.html#tab-datanode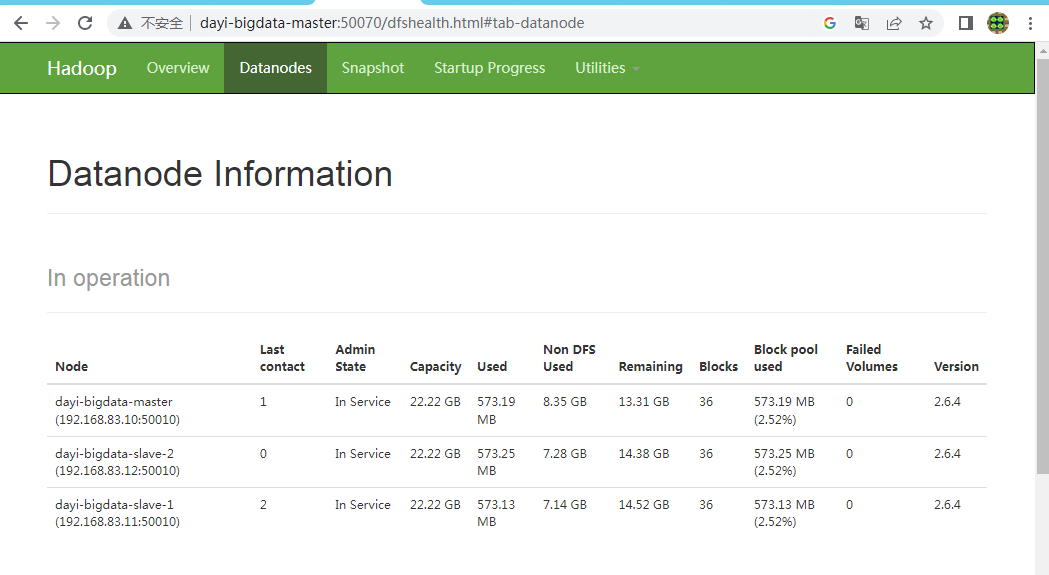
正常的话,
设置777权限
hadoop fs -chmod 777 /
6. 尝试新建目录
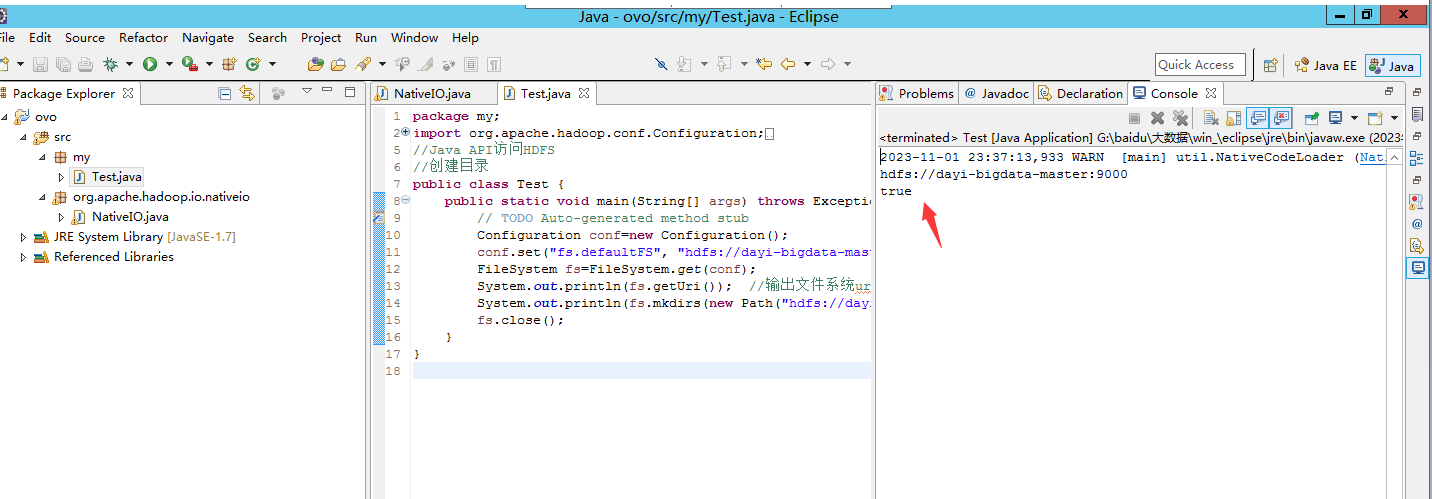
运行Test.java
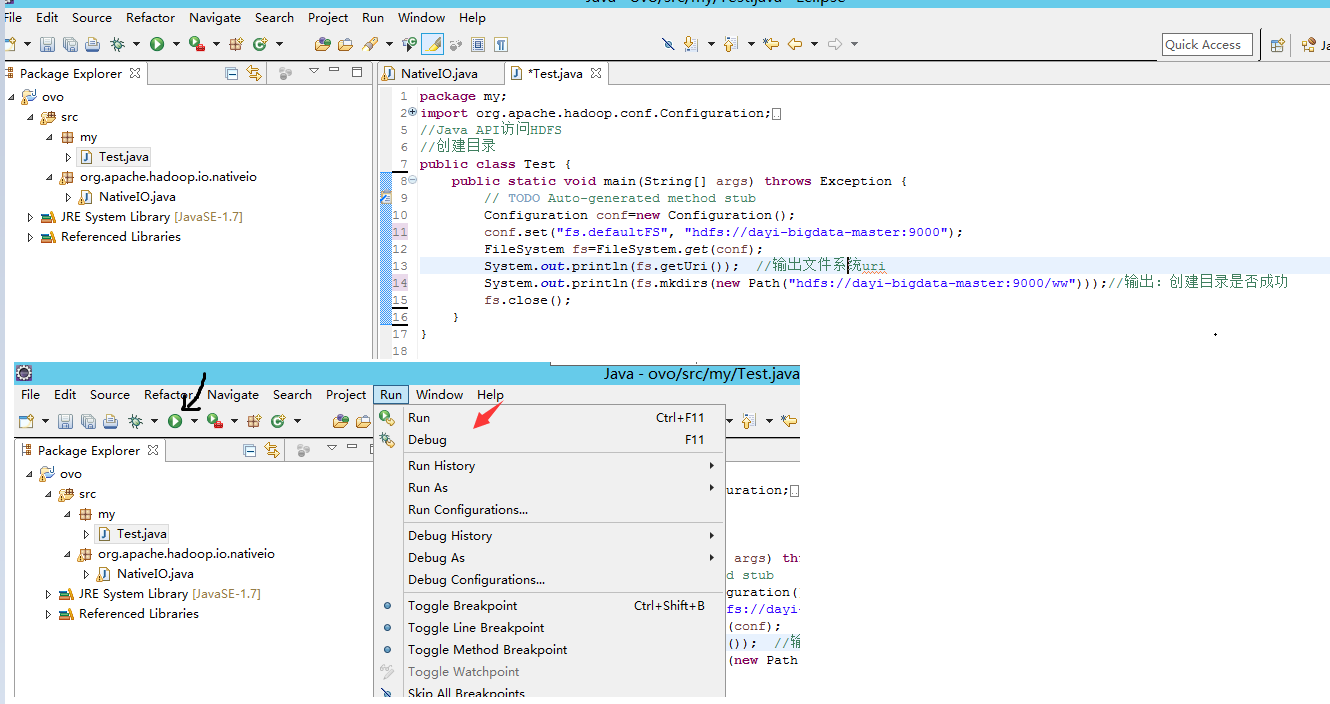
这样就好啦
单词统计
- 21 行 可能需要重新配置
存放数据源
master
mkdir -pv ~/aa
cd ~/aa
vim ~/aa/words
cat ~/aa/words
[dayi@dayi-bigdata-master aa]$ cat ~/aa/words
ovo ovo
Hello words
Pig man
ZOOKEEPER
HADOOP
Hello words
ovo ovo
Zhangsan like pigman
Do u wanna build a snowman?
Come on let’s go and play!
I never see you anymore
come out the door
上传words
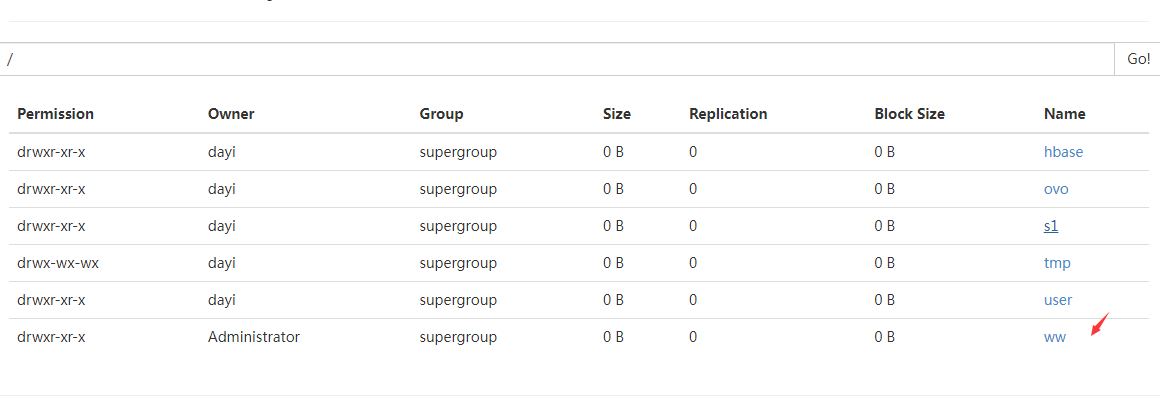
- 目录是否正常
hadoop fs -ls /
Found 6 items
drwxr-xr-x - dayi supergroup 0 2023-10-26 17:09 /hbase
drwxr-xr-x - dayi supergroup 0 2023-10-11 14:43 /ovo
drwxr-xr-x - dayi supergroup 0 2023-10-18 23:40 /s1
drwx-wx-wx - dayi supergroup 0 2023-10-18 23:57 /tmp
drwxr-xr-x - dayi supergroup 0 2023-10-18 23:01 /user
drwxr-xr-x - Administrator supergroup 0 2023-11-01 23:37 /ww
[dayi@dayi-bigdata-master aa]$
要有这个/ww目录
没有的话
hadoop fs -mkdir /ww
hadoop fs -chmod 777 /ww- 上传文件
hadoop fs -put ~/aa/words /ww
hadoop fs -cat /ww/words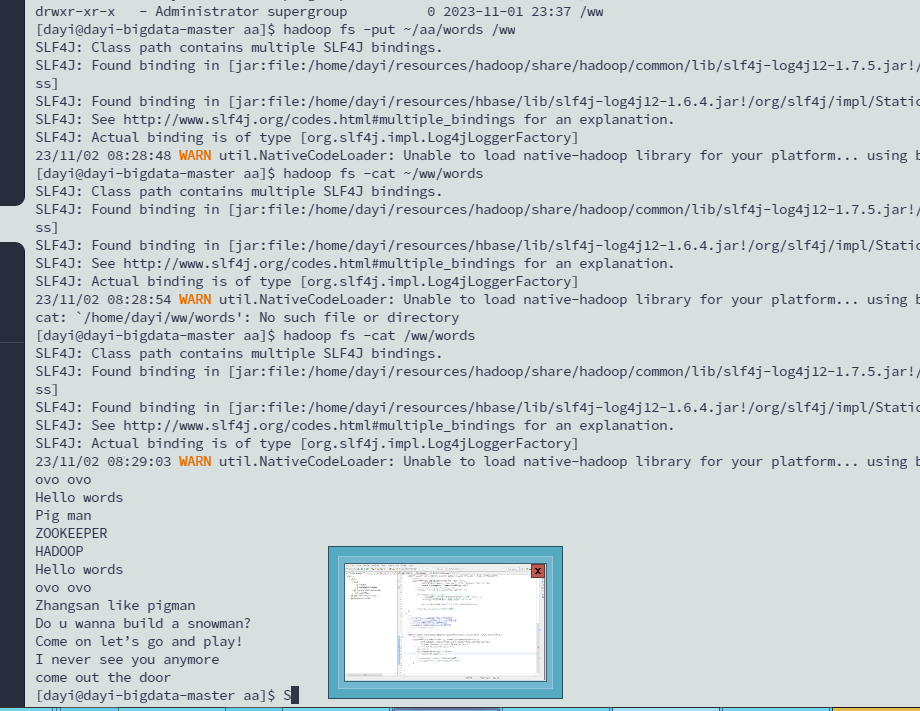
运行程序
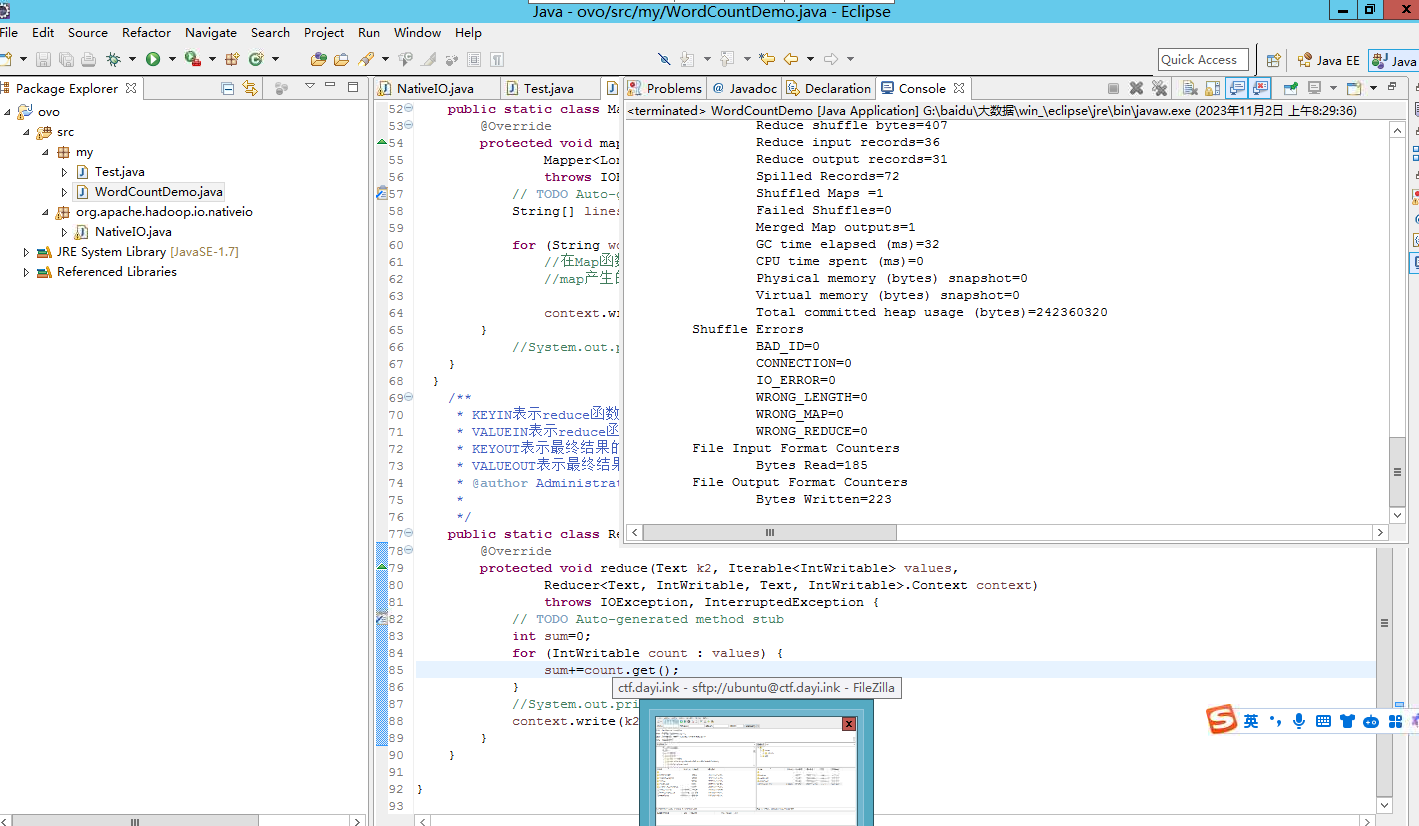
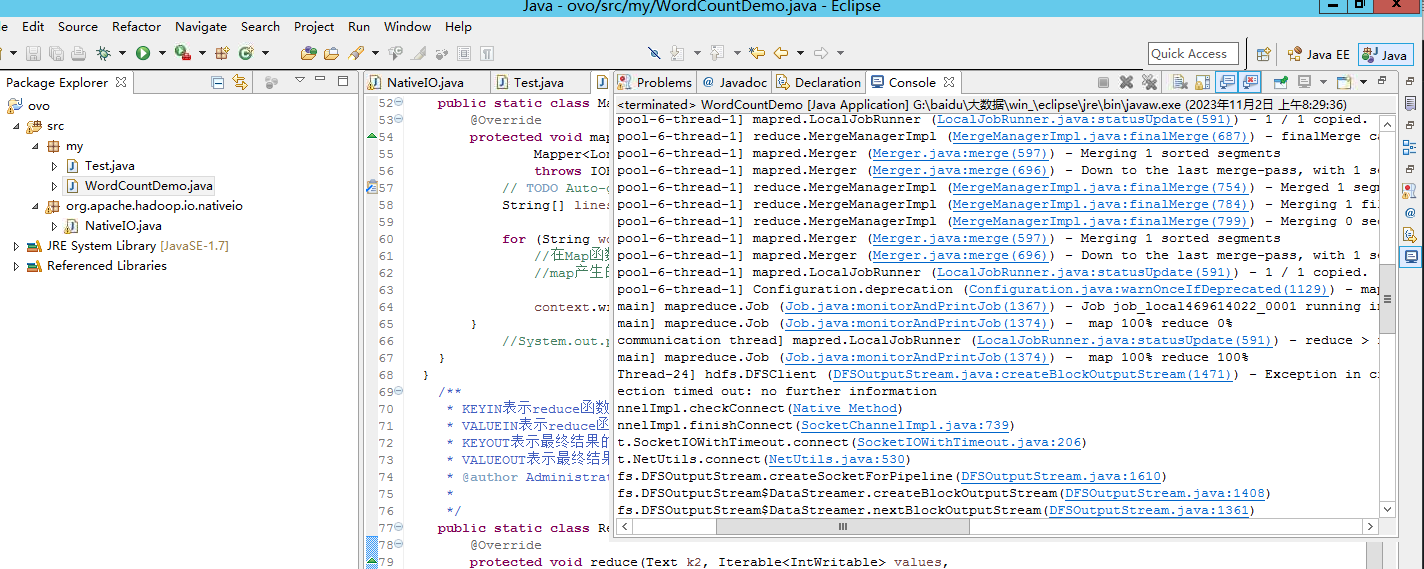
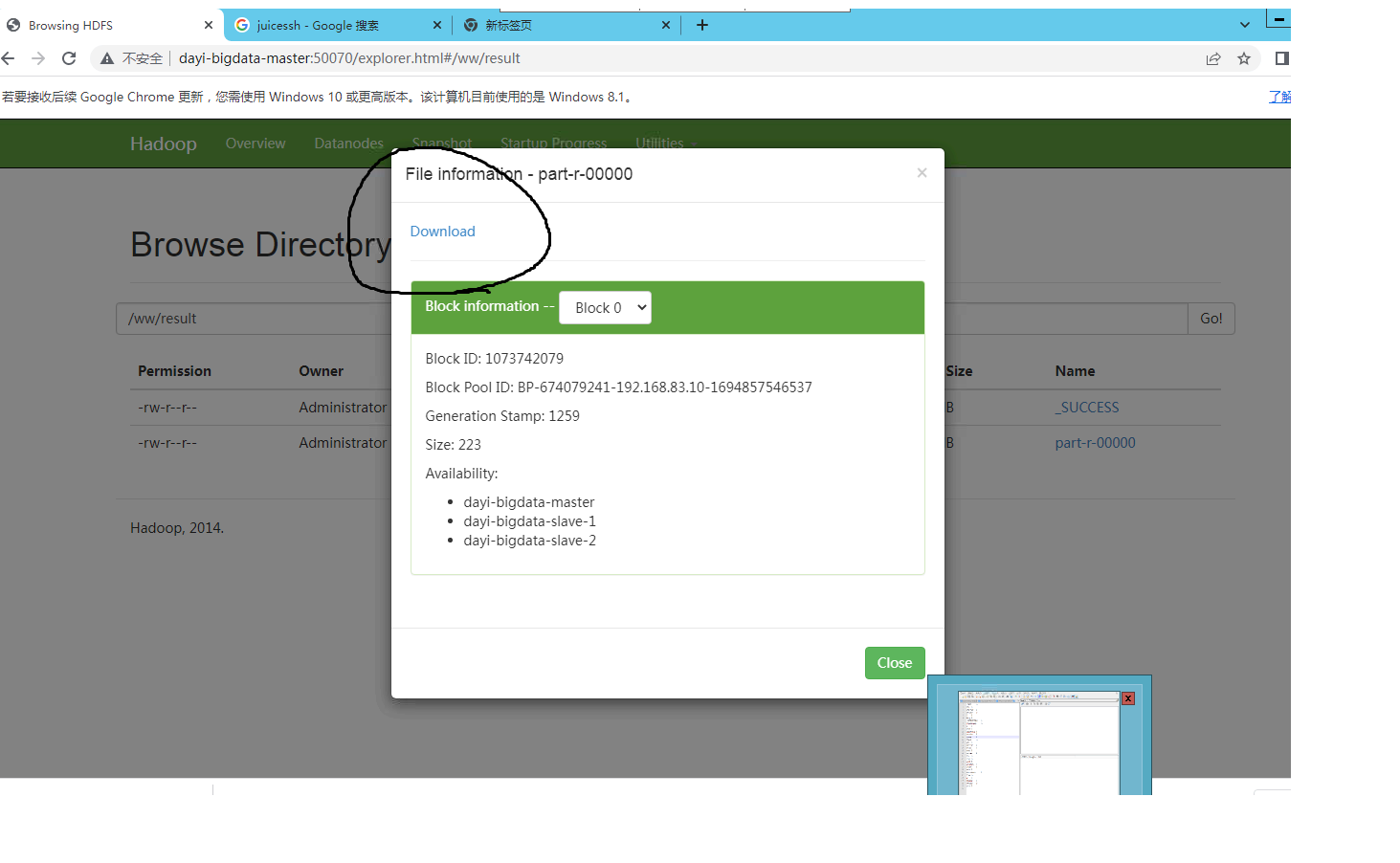
查看文件:
http://master:50070/explorer.html#/ww/result
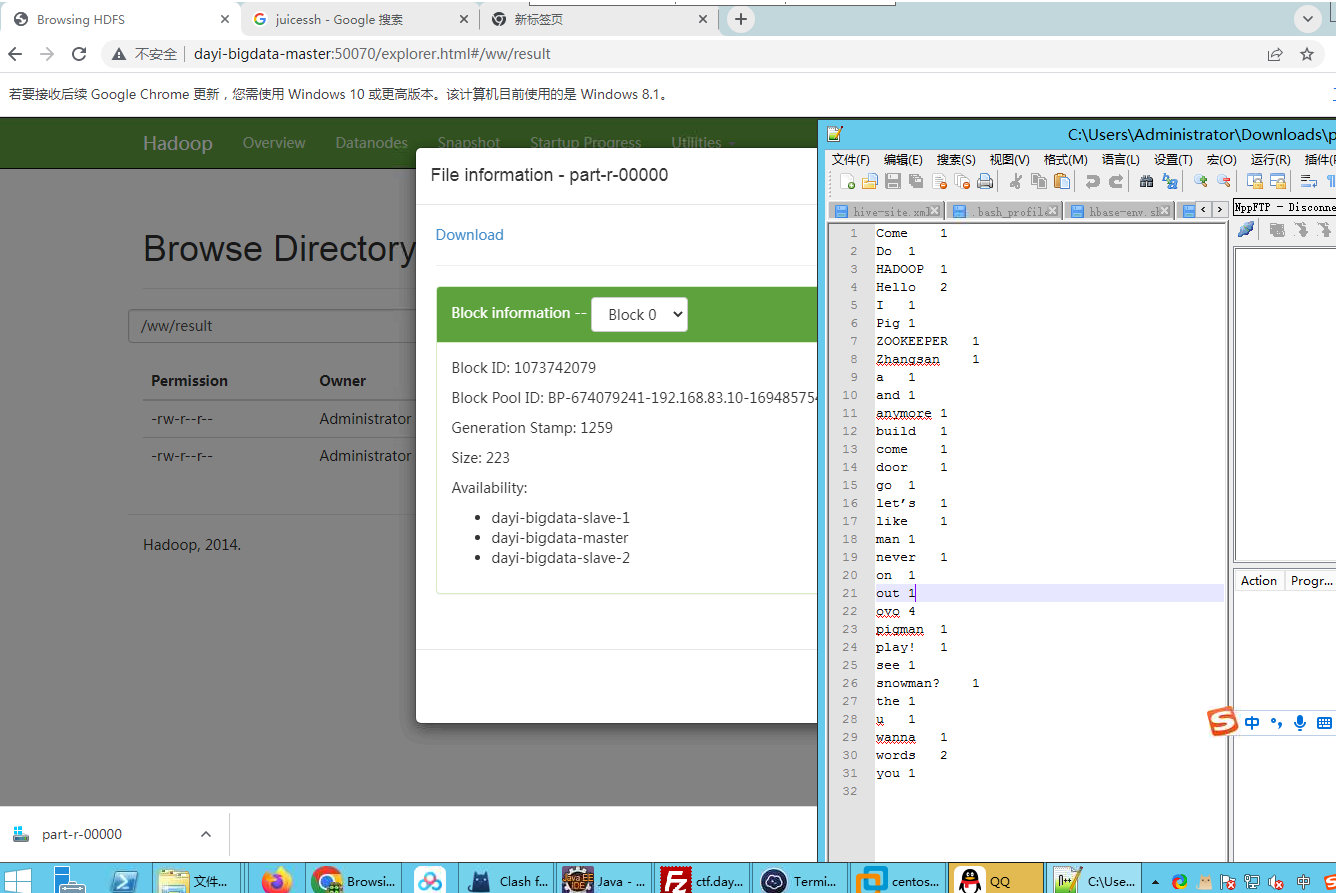
21 mapperreduce 代码
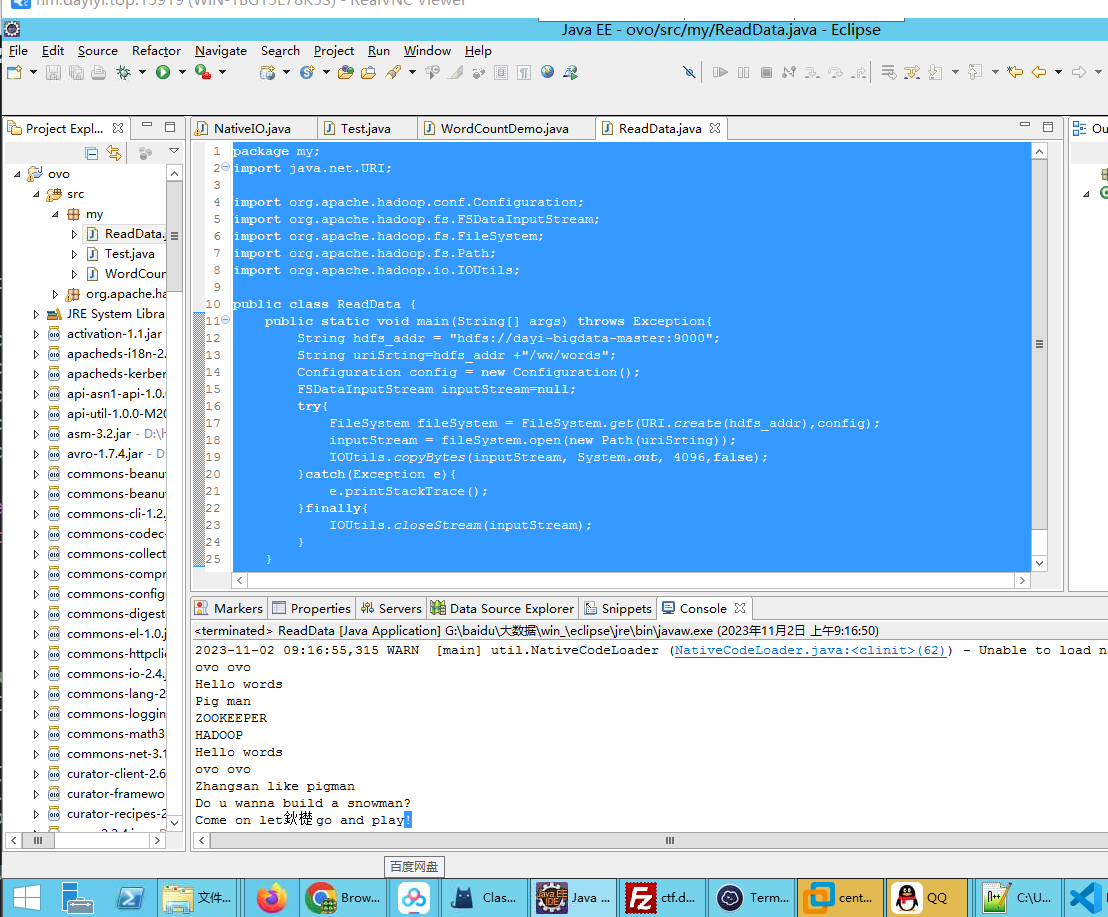
读取文件
package my;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class ReadData {
public static void main(String[] args) throws Exception{
String hdfs_addr = "hdfs://dayi-bigdata-master:9000";
String uriSrting=hdfs_addr +"/ww/words";
Configuration config = new Configuration();
FSDataInputStream inputStream=null;
try{
FileSystem fileSystem = FileSystem.get(URI.create(hdfs_addr),config);
inputStream = fileSystem.open(new Path(uriSrting));
IOUtils.copyBytes(inputStream, System.out, 4096,false);
}catch(Exception e){
e.printStackTrace();
}finally{
IOUtils.closeStream(inputStream);
}
}
}
新建目录
上传文件
package my;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class PutFile {
public static void main(String[] args) {
String hdfs_addr = "hdfs://dayi-bigdata-master:9000";
try{
FileSystem fileSystem = FileSystem.get(URI.create(hdfs_addr),new Configuration());
Path src = new Path("C:\\Windows\\System32\\drivers\\etc\\hosts");
Path desc=new Path(hdfs_addr+"/ww/ff");
fileSystem.copyFromLocalFile(src, desc);
}catch (Exception e){
e.printStackTrace();
}
}
}
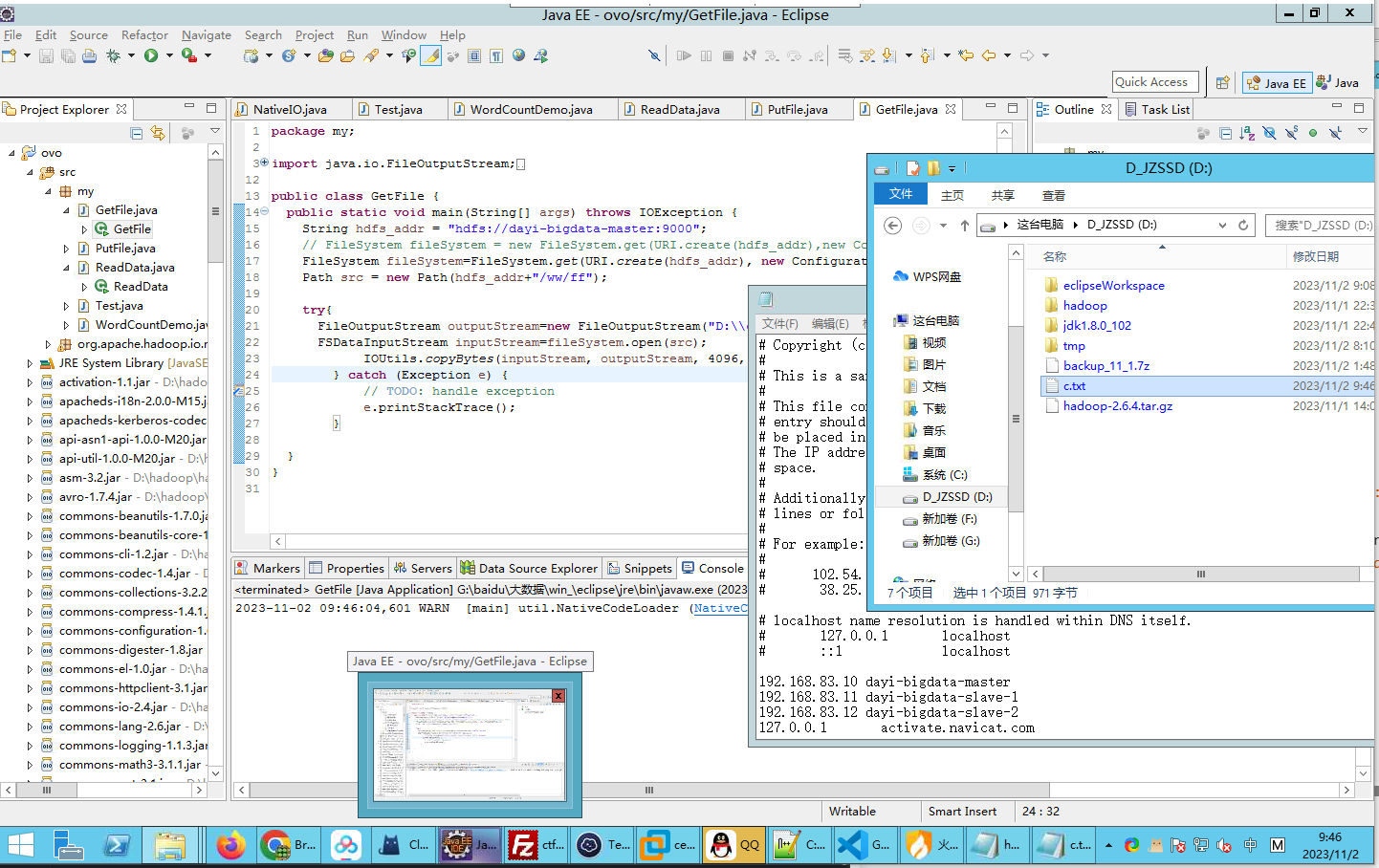
下载文件
hadoop fs -chmod 777 /ww/ffpackage my;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class GetFile {
public static void main(String[] args) throws IOException {
String hdfs_addr = "hdfs://dayi-bigdata-master:9000";
// FileSystem fileSystem = new FileSystem.get(URI.create(hdfs_addr),new Configuration());
FileSystem fileSystem=FileSystem.get(URI.create(hdfs_addr), new Configuration());
Path src = new Path(hdfs_addr+"/ww/ff");
try{
FileOutputStream outputStream=new FileOutputStream("D:\\c.txt");
FSDataInputStream inputStream=fileSystem.open(src);
IOUtils.copyBytes(inputStream, outputStream, 4096, false);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
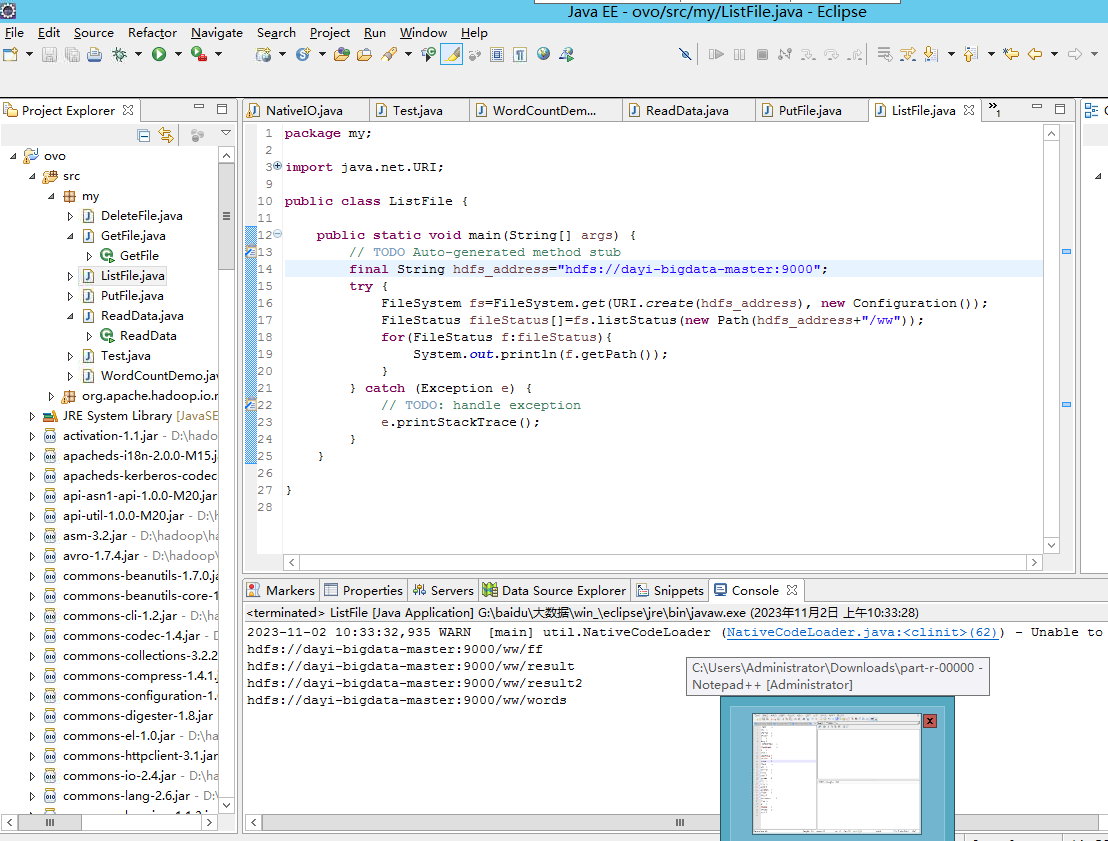
列表
下发源文件
删除文件
下发文件
结束
OVO